6. Analysis Plugins¶
The following plugins perform analysis on localisation results.
The plugins are described in the following sections using the order presented on the
Plugins > GDSC SMLM > Analysis
menu.
6.1. Drift Calculator¶
Stabilises the drift in the image by calculating the drift for each frame and applying it to correct the positions of the localisations.
Drift can be calculated using:
Method |
Description |
|---|---|
Localisation Sub-images |
Subsets of the localisation data are used to build images that are aligned to the global image. |
Drift file |
The drift is loaded from file. This file can be created by saving the drift from another calculation method. |
Marked ROIs |
The positions of fiducial markers are aligned to their centre-of-mass over the entire image. Available when ROIs have been added to the |
Reference Stack Alignment |
Images from a reference stack (e.g. a white light image) are aligned to a global projection. Available when a stack image is open. |
Further details of the methods are shown in the sections below.
Each method will produce an X and Y offset (drift) for specified frames. (Not all frames must have a drift value.) The calculated values are smoothed using LOESS smoothing (a local regression of the points around each value). The drift error is calculated as the total sum of the drift per frame. The current drift is applied to the results and the drift calculation repeated. This process is iterated until the drift has converged (shown by a small relative change in the drift error). In the case of loading the curve from file, no iteration is performed but the drift points may be smoothed.
The calculated drift curve is interpolated to assign values for any frames without a drift value. Any frames outside the range of frames with drift values can be extrapolated using different options.
The plugin requires the following parameters:
Parameter |
Description |
|---|---|
Input |
Select the results set to analyse. Fitting results can be stored in memory by the |
Method |
The method for calculating the drift curve. |
Max iterations |
The maximum number of iterations when calculating the drift curve. |
Relative error |
Stop iterating when the relative change in the total drift is below this level. |
Smoothing |
The window width to use for LOESS smoothing (values below 0.1 are unstable for small datasets). Set to zero to ignore smoothing. |
Limit smoothing |
Select this option to adjust the smoothing parameter so that smoothing uses a number of points within the configured minimum or maximum. |
Min smoothing points |
The minimum number of points to use for LOESS smoothing. |
Max smoothing points |
The maximum number of points to use for LOESS smoothing. A lower value will allow the drift curve to track the raw drift data more closely but may start to model noise. |
Smoothing iterations |
The number of iterations for LOESS smoothing. 1 is usually fine. |
Extrapolation |
The method to extrapolate the curve beyond the end points.
|
Plot drift |
Produce an output of the drift for the X and Y shifts. Shows the raw drift correction for each frame and the smoothed correction (see Figure 6.1). Use this option to see the effects of different smoothing parameters before applying the drift correction to the data. |
An example of a calculated drift curve is shown in Figure 6.1. The drift curves show that drift in the X and Y axis are independent and drift may be approximately constant (X-drift) or can vary during the course of the image acquisition (Y-drift).
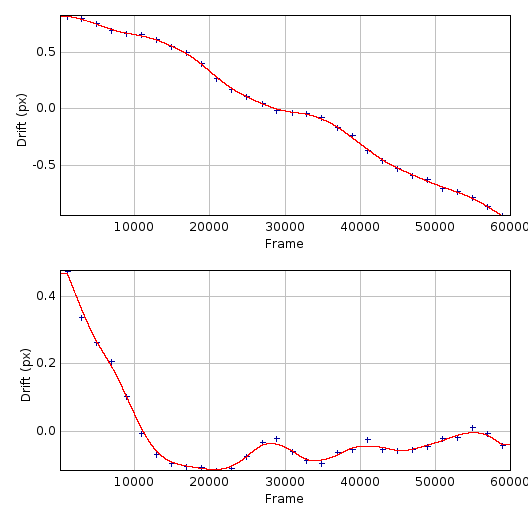
Fig. 6.1 Plot of the X-drift (top) and Y-drift (bottom) following drift calculation using the localisation sub-images method.¶
The STORM dataset consisted of 410,000 results over 60,000 frames. Sub-images were produced using 2,000 frames, raw drift calculated (blue) and smoothed using LOESS with a maximum of 4 points before interpolation to the drift curve (red).
When the drift analysis is complete the plugin will present a dialog asking the user what to do with the drift curve (Figure 6.2).
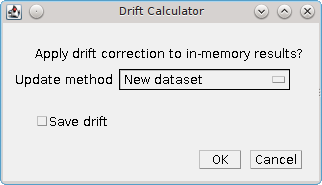
Fig. 6.2 Drift calculator curve options dialog¶
The following options are available:
Parameter |
Description |
|---|---|
Update method |
|
Save drift |
Save the drift curve to file. The plugin will prompt the user for a filename. The drift curve can later be loaded by the |
Note that if the drift correction is used to update the results then only the results held in memory will change. Any derived output, for example a table of the results or a reconstructed image, will have to be regenerated from the new results.
Example images showing the original and drift corrected localisations following sub-image alignment are shown in Figure 6.3. The drift correction curve for the image data is shown in Figure 6.1. Note how drift correction has removed the blur from the main image and resolved smeared spots into single points.
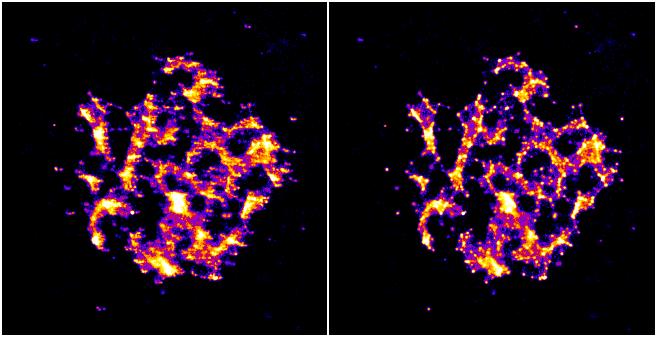
Fig. 6.3 Example of drift correction.¶
Left: Original localisations; Right: Drift corrected localisations.
Details of the different drift calculation methods are shown below.
6.1.1. Sub-Image Alignment¶
If the localisations represent a structural image then a subset of the localisations will also represent the same structure. Where there are a large number of localisations (for example in STORM images) it is possible to create sub-images from sub-sets of the data and align them.
The Sub-image alignment method performs the following steps:
Initialise the drift for each time point to zero.
Produce sub-images from N consecutive frames using the coordinates from the localisations plus the drift for that time point.
Combine all sub-images to a master projection.
Aligns each sub-image to the master projection using correlation analysis. The drift time point is set using the average frame from all the localisations in the sub-image.
Smooth the drift curve.
Calculate the change to the drift and repeat from step 2 until convergence.
The following parameters can be specified:
Parameter |
Description |
|---|---|
Frames |
The number of consecutive frames to use to construct each sub-image. |
Minimum localisations |
The minimum number of localisations used for a sub-image. If the frames for a sub-image do not contain enough localisations then they will be combined with the next set of frames until an image is produced with the minimum number of localisations. |
FFT size |
Specify the size of the reconstructed image. Note that large images:
|
6.1.2. Drift File¶
The drift can be loaded directly from file. The file must contain delimited records of:
Time X Y
The fields can be delimited with tabs, spaces or commas. Any line not starting with a digit is ignored. Only the time-points that are within the time range of the input results are used.
The file is assumed to contain the final drift curve and no iterations are performed to update the curve. The curve may be smoothed using LOESS smoothing before being interpolated and applied to the data.
The Drift File method allows the same drift to be applied to multiple data sets. For example if an image is produced with a white light channel for drift tracking and two different colour channels with localisation data the same drift from the white light image can be used to correct both sets of localisations.
6.1.3. Reference Stack Alignment¶
The drift can be calculated using a reference stack image, for example this may be a white light image taken during the experiment. The reference stack must be a single stack image. Some microscopes may make a separate image during acquisition for the white light. However if all the frames are joined into a master image then you can extract reference stack slices from a master image using ImageJ’s Substack Maker plugin (Image > Stacks > Tools > Make Substack...).
The slice numbers in the reference stack will not correspond to the slices in the localisation results. Therefore the plugin allows the user to specify the actual slice number of the first slice in the reference stack (start frame), and then the frame spacing between slices in the stack. The actual frame for the stack is then calculated as the previous frame (starting from the start frame) plus the frame spacing.
The
Reference Stack Alignment
method performs the following steps:
Initialise the drift for each time point to zero
Calculate an average projection of the slices shifted by the current drift
Aligns each slice to the average projection using correlation analysis to compute the drift
Smooth the drift curve
Calculate the change to the drift and repeats from step 2 until convergence
The following parameters can be specified:
Parameter |
Description |
|---|---|
Start frame |
The actual slice number from the original image for the first frame from the reference stack. |
Frame spacing |
The number of frames from the original image between each slice in the reference stack. |
For example if a white light image was taken at the start and then every 20 frames then the method should be called with parameters start_frame=1 frame_spacing=20. The drift will then be calculated as if the n slices were at time points:
1, 21, 41, ..., 20 * (n-1) + 1, 20 * n + 1
6.1.4. Fiducial Markers¶
This method uses constant fiducial markers that are placed within the image to allow the drift to be tracked (e.g. fluorescent beads). The method is only available in the drop-down options when there are ROIs listed in the ImageJ ROI manager.
Rectangular ROIs can be placed around the fiducial markers on the original image and then added to the ROI manager (press Ctrl+T). The ROIs do not have to be marked on the original image. Note however that each ROI’s bounds (x,y,width,height) are used to find spots within the input localisations and must correspond to the original image pixels. For example the ROIs can be marked on an image with the same pixel dimensions as the original image such as an average intensity projection or a super-resolution reconstruction of the data made using an image scale of 1. This type of image can be created using the Image output option of the Results Manager plugin.
All the ROIs in the manager will be used to calculate the drift. Ensure that you choose regions containing a constant bright spot that is present through the majority of frames. If multiple spots are within the ROI only the brightest one per frame will be used. Ideally these are fluorescent beads added to the image as fiducial markers.
The Marked ROIs method performs the following steps:
Initialise the drift for each time point to zero.
Calculate the centre-of-mass of all the spots selected within each ROI.
For each frame and each ROI, calculate the shift from the spot to the centre-of-mass of the ROI.
For each frame, produce a combined shift using a weighted average of the shift from each ROI. The weight is the spot signal (number of photons).
Smooth the drift curve.
Calculate the change to the drift and repeats from step 2 until convergence.
The Marked ROIs method requires no additional parameters, only ROIs within the ROI Manager.
6.1.5. Image Alignment using Correlation Analysis¶
Image alignment in the Sub-image alignment and Reference Stack Alignment methods is done using the maximum correlation between images (including sub-pixel registration using cubic interpolation). This is computed in the frequency domain after a Fast Fourier Transform (FFT) of the image. The method of producing and then aligning images is computationally intensive so the plugin uses multi-threading to increase speed. The number of threads to use is the ImageJ default set in Edit > Options > Memory & Threads....
6.2. Trace Molecules¶
Traces localisations through time and collates them into traces using time and distance thresholds. Each trace can only have one localisation per time frame. With the correct parameters a trace should represent all the localisations of a single fluorophore molecule including blinking events.
6.2.1. Molecule Tracing¶
The fluorophores used in single molecule imaging can exist is several states. When in an active state it can absorb light and emit it at a different frequency (fluorescence). The active state can move into a dark state where it does not fluoresce. The dark state can move back to the active state. Eventually the molecule moves into a bleached state where it will no longer fluoresce (photo-bleached). The rates of the transitions between states are random as are the number of times this can occur. This means that it is possible for the same molecule to turn on and off several times causing blinking.
To prevent over-counting of molecules due to blinking it is possible to trace the localisations through time. Any localisation that occurs very close to another localisation from a different frame may be the same molecule. The distance between localisations can be spatial or temporal. Using two parameters it is possible to trace localisations using the following algorithm:
Any spot that occurred within time threshold and distance threshold of a previous spot is grouped into the same trace as that previous spot. Note that existing traces are identified only by their last known position, not all previous positions. In the event of multiple candidate connections the algorithm assigns the closest distance connection first. The previous time frames can be searched using all time frames together, or iteratively using each time frame within the time threshold either in earliest or latest order. Matching uses a greedy nearest neighbour algorithm and may not achieve the maximum cardinality matching for the specified distance threshold.
To remove the possibility for overlapping tracks the plugin allows the track to be excluded if a second localisation occurs within an exclusion threshold of the current track position. This ensures that the localisation assigned to the track is the only candidate within the exclusion distance and effectively removes jumps of particles that could overlap with another moving particle. Note however that the effect is to terminate the track and start a new one. This will result it over counting of molelcules and shortening of track lengths. Setting the exclusion distance to less than the distance threshold disables this feature.
When all frames are processed the resulting traces are assigned a spatial position equal to the centroid position of all the spots included in the trace.
An optimisation method for selecting the time and distance thresholds is provided based on the work of Coltharp, et al (2012).
6.2.2. Trace Molecules Plugin¶
The Trace Molecules plugin allows temporal tracing to be performed on localisations loaded into memory. Figure 6.4 shows the plugin dialog.
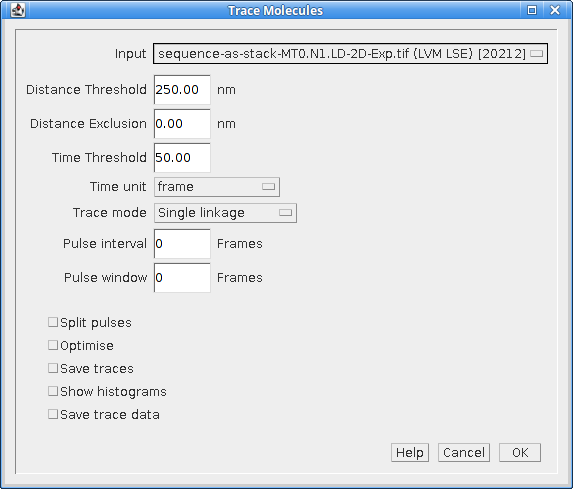
Fig. 6.4 Trace Molecules dialog¶
The following parameters can be configured:
Parameter |
Description |
|---|---|
Input |
Specify the localisations to use. |
Distance Threshold (nm) |
Maximum distance (in nm) for two localisations to belong to the same trace. Zero is supported to find colocated localisations. This is useful for analysis of ground-truth data from a simulation. |
Distance exclusion (nm) |
Exclusion distance (in nm) where no other localisations are allowed. Use this setting to be sure that a trace links together localisations that are not close to any other localisations. Ignored if less than the distance threshold. |
Time Threshold |
Maximum time separation for two localisations to belong to the same trace (should cover a minimum of 1 frame). |
Time unit |
The unit for the |
Trace mode |
|
Pulse interval |
Sets the pulse interval for traces (in frames). Set to zero to disable pulse analysis. See section 6.2.2.1: Pulse Analysis. |
Pulse window |
Sets the pulse window for traces (in frames). Set to zero to disable pulse analysis. See section 6.2.2.1: Pulse Analysis. |
Split pulses |
Enable this to split traces that span the a pulse boundary into separate traces. Use this setting if your imaging conditions use pulsed activation and you have imaged for long enough between pulses to be sure that all fluorophores have photo-bleached. |
Save derived datasets |
Enable this to save derived datasets to memory such as the singles, multi, and centroids. |
Optimise |
If selected the plugin will provide a second dialog that allows a range of distance and time thresholds to be enumerated (see section 6.2.3: Optimisation). |
Save traces |
When the tracing is complete, show a file selection dialog to allow the traces to be saved. |
Show histograms |
Present a selection dialog that allows histograms to be output showing statistics on the traces, e.g. total signal, on time and off time. |
Save trace data |
Save all the histogram data to a results directory to allow further analysis. A folder selection dialog will be presented after the tracing has finished. |
The plugin will trace the localisations and store the results in memory with a suffix Traced. Additional derived datasets are optionally created: all single localisations which could not be joined are given a suffix Trace Singles; all traces are given a suffix Traced Multi; the centroids of all traces are given the suffix Traced Centroids; and the centroids of the traces-only are given the suffix Traced Centroids Multi. Note: The Traced Singles plus Traced Multi datasets equals the Traced dataset.
A summary of the number of traces is shown on the ImageJ status bar. The results are accessible using the Results Manager plugin.
6.2.2.1. Pulse Analysis¶
The options Pulse Interval and Pulse Window allow the user to specify a repeating period within the image time sequence. Only traces that originate within a frame defined by the pulse will be included in the output.
For example a pulse could be defined using Pulse Interval 30 and Pulse Window 3. Only traces that have their first localisation in frames 1-3, 31-33, 61-63, etc. will be output in the final traces.
This option was added to allow analysis of images acquired using a pulsed activation laser. Consequently only localisations that could be traced back to a short period after the activation pulse are of interest. All other localisations are likely to be random background fluorescence events.
The options should be disabled when using a continuous activation laser by setting to the parameters to zero.
When using a pulse activation it is possible to photo-bleach all fluorophores that were activated by the pulse before the next pulse. This requires a long pulse interval. If you are confident that all molecules have bleached then it does not make sense for a trace to span pulse intervals. Use the Split pulses option to break apart any traces that span a pulse interval boundary into separate traces.
6.2.3. Optimisation¶
It is possible to produce an estimate of the optimum distance and time thresholds if the blinking rate of the fluorophore is known. Note that the blinking rate can be estimated from the data using the
Blink Estimator plugin (see 6.17: Blink Estimator). Alternatively it can be measured by manual inspection of purified single fluorophores sufficiently spread on a slide to avoid two molecules in the same location. Care must be taken to ensure that the imaging condition are the same as those used for
in vivo
experiments.
The optimisation method is adapted from Coltharp, et al (2012). Optimisation is based on the following equation:
The observed pulses is the number of single pulse events that are observed in the data, i.e. continuous emission from the same fluorophore. Dividing this by the average blinking rate of a fluorophore should give the number of molecules.
The observed pulses can be found by tracing the localisations using a time threshold of 1 frame and a distance threshold that will allow a match of the same molecule position. This will only join localisations that are in adjacent frames into a single light pulse. The distance to use is obtained from the data using 2.5x the average localisation precision.
For example if 10,000 pulses have been identified by tracing at t=1, d=2.5 x Av. Precision and the blinking rate is known to be 2 then the expected number of molecules is 5,000.
A score metric can be computed for a given tracing result:
The closer the score to zero, the more likely that the tracing parameters are correct. In addition a negative score indicates over-clustering, a positive score is under-clustering. Consequently a plot of the distance and time thresholds verses the score will indicate the parameters that are best suited to achieving a zero score. The zero score can be more easily seen on such a plot by using the absolute value of the score.
The following table describes the parameters used during the optimisation:
Parameter |
Description |
|---|---|
Min Distance Threshold (nm) |
The minimum distance threshold. |
Max Distance Threshold (nm) |
The maximum distance threshold. |
Min Time Threshold (seconds) |
The minimum time threshold. |
Max Time Threshold (seconds) |
The maximum time threshold. |
Steps |
The number of steps to use between the minimum and maximum. Steps intervals are chosen using a geometric (not linear) scale to bias sampling towards lower threshold values. |
Blinking rate |
The average blinking rate of the fluorophore. Must be above 1 (otherwise no occurrences of repeat molecules are expected). Note that the blinking rate is equal to the number of blinks + 1. |
Plot |
Produce a plot of the score against the time/distance threshold:
|
When the optimisation option is selected it is preferable to choose a plot option. An ideal plot will show an inverted L-shape as shown in Figure 6.5. The parameters that achieve a score close to zero are shown in black. The scale of the image has been calibrated to use the scale of the distance and time thresholds. Therefore hovering over a part of the image will show the time (X-axis) and distance (Y-axis) threshold required for the given score.
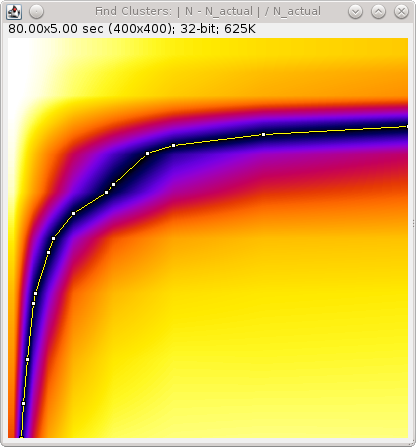
Fig. 6.5 Output plot from the Trace Molecules optimisation algorithm.¶
The plot shows the absolute score against the time (X-coordinate) and distance (Y-coordinate) thresholds.
Note that at the end of optimisation the thresholds are automatically set using the zero score that is closest on the plot to the origin. This should be a compromise point between the two thresholds. The values used will be written to the ImageJ log window. The tracing algorithm then runs and the traces are stored in memory.
If the optimised thresholds are not suitable it is left to the user to interpret the plot of the scores and select the best values. For example this could be done by assuming the distance threshold calculated using 2.5 x Av. Precision is correct and looking up the corresponding time threshold when the score is zero.
6.2.4. Memory Output¶
The tracing algorithm assigns a unique ID to each trace. All the localisations that are a member of that trace are assigned the same ID. The results are then saved into memory. The results are named using the input results set name plus a suffix as follows:
Suffix |
Description |
|---|---|
Traced |
A full set of localisations with each assigned the corresponding trace ID. |
Trace Centroids |
The localisations of each trace combined into a centroid. Centroids have a signal equal to the sum of the localisations, the coordinates are set using the signal weighted centre-of-mass of the localisations. The background is averaged and the noise combined using the root of the sum-of-squares. The Gaussian standard deviation of the localisation is set using the average precision of the localisations, calculated using the Mortensen formula. |
Trace Singles |
Contains the localisations that were not part of a trace, i.e. are a single localisation. |
Trace Multi |
Contains the localisations that were part of a trace, i.e. are a multi-frame localisation. |
Trace Centroids Multi |
The localisations of each trace combined into a centroid. Only traces with multiple localisations are included. |
It is possible to save these results to file using the
Results Manager
plugin.
6.2.5. File Output¶
If the Save traces option is selected then the plugin will show a file selection dialog allowing the user to choose the location of the clusters results file. The results will use the same format as the plain-text file results option in the Peak Fit and Results Manager plugins. However all the localisations for each trace will be stored together under a Trace entry. The Trace entry will have the format:
#Trace x y (+/-sd) n=[n], b=[n], on=[f], off=[f], signal=[f]
where:
x&yare the coordinates of the centroidsdis the standard deviation of distances to the centroidnis the size of the clusterbis the number of pulses (bursts of continuous time frames)onis the average on-time of each pulseoffis the average off-time between each pulsesignalis the total signal for all the localisations in the trace
The prefix # character allows the clusters to be ignored as comments, for example when the cluster file is loaded as a results file.
Note that the number of pulse (or bursts) is equal to the number of blinks + 1. It is equivalent to the blinking rate of the molecule.
6.3. Cluster Molecules¶
Cluster localisations into clusters using distance and optionally time thresholds. When using a time threshold each cluster can only have one localisation per time frame. With the correct parameters a cluster should represent all the localisations of a single fluorophore molecule including blinking events.
This plugin is very similar to the Trace Molecules plugin (section 6.2) and many of the options are the same. Key differences are that Cluster Molecules can join clusters together, can join multiple localisations in the same frame, can join new localisations based on the distance to any localisation in a cluster and can measure distances to the cluster centroid. The Trace Molecules algorithm only joins single localisations to an existing track based on the distance between the closest localisations in time, and requires only 1 localisation per frame in a track. Cluster Molecules can be used to aggregate more than 1 molecule; Trace Molecules is used to aggregate localisations from the same molecule over time.
The following options are available:
Parameter |
Description |
|---|---|
Input |
Specify the localisations. |
Distance Threshold (nm) |
Maximum distance (in nm) for two localisations to belong to the same cluster. Zero is supported to find colocated localisations. This is useful for analysis of ground-truth data from a simulation. |
Time Threshold |
Maximum time separation for two localisations to belong to the same trace (should cover a minimum of 1 frame). Note: This is only used for some algorithms. |
Time unit |
The unit for the |
Clustering algorithm |
Set the clustering algorithm. See section 6.3.1: Clustering Algorithms. |
Pulse interval |
Sets the pulse interval for clusters (in frames). Clusters will only contain localisations from within the same pulse. Set to zero to disable pulse analysis. See section 6.2.2.1: Pulse Analysis. |
Split pulses |
Enable this to ensure clusters contain only localisations within a single pulse (defined by the Use this setting if your imaging conditions use pulsed activation and you have imaged for long enough between pulses to be sure that all fluorophores have photo-bleached. |
Save derived datasets |
Enable this to save derived datasets to memory such as the singles, multi, and centroids. |
Save clusters |
When the clustering is complete, show a file selection dialog to allow the clusters to be saved. |
Show histograms |
Present a selection dialog that allows histograms to be output showing statistics on the clusters, e.g. total signal, on time and off time. |
Save cluster data |
Save all the histogram data to a results directory to allow further analysis. A folder selection dialog will be presented after the clustering has finished. |
The plugin will cluster the localisations and store the results in memory with a suffix Clustered. Additional derived datasets are optionally created: all single localisations which could not be joined are given a suffix Clustered Singles; all clusters are given a suffix Clustered Multi; the centroids of all clusters are given the suffix Clustered Centroids; and the centroids of the clusters-only are given the suffix Clustered Centroids Multi. Note: The Clustered Singles plus Clustered Multi datasets equals the Clustered dataset.
A summary of the number of clusters is shown on the ImageJ status bar. The results are accessible using the Results Manager plugin.
6.3.1. Clustering Algorithms¶
The following table lists the available clustering algorithms:
Algorithm |
Description |
|---|---|
Particle single-linkage |
Joins the closest pair of particles, one of which must not be in a cluster. Clusters are not joined and can only grow when particles are added. |
Centroid-linkage |
Hierarchical centroid-linkage clustering by joining the closest pair of clusters iteratively. |
Particle centroid-linkage |
Hierarchical centroid-linkage clustering by joining the closest pair of any single particle and another single or cluster. Clusters are not joined and can only grow when particles are added. |
Pairwise |
Join the current set of closest pairs in a greedy algorithm. This method computes the pairwise distances and joins the closest pairs without updating the centroid of each cluster, and the distances, after every join (centroids and distances are updated after each pass over the data). This can lead to errors over true hierarchical centroid-linkage clustering where centroid are computed after each link step. For example if A joins B and C joins D in a single step but the new centroid of AB is closer to C than D. |
Pairwise without neighbours |
A variant of This algorithm should return the same results as the |
Centroid-linkage (Distance priority) |
Hierarchical centroid-linkage clustering by joining the closest pair of clusters iteratively. Clusters are compared using time and distance thresholds with priority on the closest time gap (within the distance threshold). |
Centroid-linkage (Time priority) |
Hierarchical centroid-linkage clustering by joining the closest pair of clusters iteratively. Clusters are compared using time and distance thresholds with priority on the closest distance gap (within the time threshold). |
Particle centroid-linkage (Distance priority) |
Hierarchical centroid-linkage clustering by joining the closest pair of any single particle and another single or cluster. Clusters are not joined and can only grow when particles are added. Clusters are compared using time and distance thresholds with priority on the closest time gap (within the distance threshold). |
Particle centroid-linkage (Time priority) |
Hierarchical centroid-linkage clustering by joining the closest pair of any single particle and another single or cluster. Clusters are not joined and can only grow when particles are added. Clusters are compared using time and distance thresholds with priority on the closest distance gap (within the time threshold). |
Only the (Distance priority) and (Time priority) methods use the time information. All the other algorithms will ignore the Time Threshold and optional Pulse interval parameters.
All the clustering algorithms (except Pairwise) are multi-threaded for at least part of the algorithm. The number of threads to use is the ImageJ default set in Edit > Options > Memory & Threads....
The Pairwise algorithm is not suitable for multi-threaded operation but is the fastest algorithm by an order of magnitude over the others. All other algorithms have a similar run-time performance except the Pairwise without neighbours algorithm which doesn’t just search for the closest clusters but also tracks the number of neighbours. The algorithm should return the same results as the Centroid-linkage algorithm but the analysis of neighbours has run-time implications. At very low densities this algorithm is faster since all pairs without neighbours can be joined in one step. However at most normal and high densities tracking neighbours is costly and the algorithm is approximately 3x slower than the next algorithm.
6.4. Dynamic Trace Molecules¶
Traces localisations through time and collates them into traces using a probability model to reconnect localisations to existing traces based on diffusion coefficient, intensity and fluorophore disappearance rate.
This plugin implements dynamic multiple target tracing based on Sergé et al (2008). Details can be found in the paper’s supplementary information appendix 2. Tracing uses a model to assign the probability that a localisation should join a current trajectory (or track). The matrix of all localisations paired with all current trajectories is considered and the maximum likelihood reconnection is selected. New trajectories are created as required and existing trajectories can expire if no localisations have been assigned to them for a set number of frames.
The probability model consists of three parts: the probability for a match given the diffusion; the probability for a match given the intensity; and the probability the trajectory blinks or disappears.
The probability for diffusion computes a probability based on the distance from the end of the trajectory to the localisation. This assumes a maximum diffusion coefficient for moving particles which sets an upper limit on the distance allowed. A moving particle may be slower than the maximum if it has become confined, for example a DNA binding protein bound to the DNA or a membrane protein that has formed a complex. The tracing thus maintains a local diffusion coefficient for each track based on the jumps observed for the previous N frames. The probability is computed as a weighted average of the probability based on maximum (unconfined) diffusion and the probability using the local diffusion rate.
The probability for intensity computes the probability that the localisation intensity is from the distribution of intensity values in the trajectory. This is the non-blinking, or on, probability for intensity. When the trajectory is short the probability function uses the population mean and standard deviation. Otherwise it uses the mean and standard deviation from the previous N frames where the trajectory was on. A second component is the probability the trajectory will blink (i.e. turn off). The final intensity probability is the weighted combination of the probability for non-blinking (on) and blinking (off). Note that the intensity statistics are only valid if the trajectory was on for the entire frame. Turning off during the frame (partial blink) will skew the statistics. Thus frames are counted as on for new localisations if the probability for non-blinking is higher than the blinking probability. The result is the previous N on frames for local statistics may span more time than N frames.
The probability for disappearance is modelled using the probability that an off trajectory will reappear. This uses an exponential decay controlled by a decay factor. A higher factor will increase the probability a trajectory reappears after a set amount of time.
The local diffusion model can be optionally disabled. The result is tracing based on a maximum diffusion rate.
The intensity model is disabled if all localisations have the same intensity (i.e. are only (x,y) positions) and can also be optionally disabled. The result is tracing based on diffusion and blinking.
Setting a disappearance threshold to 0 frames will configure tracing using diffusion and intensity with no allowed blinking. This should create tracks similar to the Nearest Neighbour trace mode but will use a maximum probability connection test and not the closest first assignment algorithm.
This plugin is very similar to the Trace Molecules plugin (section 6.2) and many of the options are the same. The following options are available:
Parameter |
Description |
|---|---|
Input |
Specify the localisations. |
Diffusion coefficient |
The expected maximum diffusion coefficient for moving particles. Used to set an upper limit on the radius allowed to reconnect trajectories and localisations. |
Temporal window |
The window over which to build local statistics |
Local diffusion weight |
The weighting for the probability created using the local diffusion coefficient; the remaining probability uses the maximum diffusion coefficient. |
On intensity weight |
The weighting for the probability for non-blinking intensity; the remaining probability uses the probability for blinking intensity. |
Disappearance decay factor |
Controls the expected duration over which an off trajectory may reappear. Higher values will increase probability the molecule may reappear after t frames. |
Disappearance threshold |
The threshold used to deactivate a trajectory. Any trajectory that has been in the off (dark) state longer than this threshold is removed and cannot connect to new localisations. |
Disable local diffusion model |
Set to true to disable the local diffusion model. The diffusion model will only use the maximum diffusion coefficient. Can be used when particles blink frequently which results in under estimation of the local diffusion using jump distances due to missing distances. |
Disable intensity model |
Set to true to disable the intensity model. Can be used when the intensity of particles in a track is highly variable and intensity cannot be used to distinguish the track. |
Defaults |
Use this button to reset the values to the defaults as used in the original source paper (Sergé et al, 2008). |
Save derived datasets |
Enable this to save derived datasets to memory such as the singles, multi, and centroids. |
Save traces |
When the tracing is complete, show a file selection dialog to allow the traces to be saved. |
Show histograms |
Present a selection dialog that allows histograms to be output showing statistics on the traces, e.g. total signal, on time and off time. |
Save trace data |
Save all the histogram data to a results directory to allow further analysis. A folder selection dialog will be presented after the tracing has finished. |
The plugin will trace the localisations and store the results in memory with a suffix Dynamic Traced. Additional derived datasets are optionally created: all single localisations which could not be joined are given a suffix Dynamic Traced Singles; all traces are given a suffix Dynamic Traced Multi; the centroids of all traces are given the suffix Dynamic Traced Centroids; and the centroids of the traces-only are given the suffix Dynamic Traced Centroids Multi. Note: The Dynamic Traced Singles plus Dynamic Traced Multi datasets equals the Dynamic Traced dataset.
A summary of the number of traces is shown on the ImageJ status bar. The results are accessible using the Results Manager plugin.
6.5. Trace Molecules (Multi)¶
This plugin allows the Trace Molecules, Cluster Molecules and Dynamic Trace Molecules plugins to be run with multiple input datasets. Each dataset will be analysed separately. This can be used to perform the same analysis on multiple datasets.
When the plugin runs a dialog allows the choice of analysis and options for multiple datasets:
Parameter |
Description |
|---|---|
Analysis mode |
The analysis mode: |
Disable combined output |
Set to true to disable combining the traces for each dataset into a combined dataset. This renumbers only the trace ID to be unique. Datasets are combined if they have the same pixel and time calibration. |
Then a dialog is presented that allows the datasets to be selected. The plugin will then show the dialog for the selected analysis mode. See the relevant plugin’s documentation for details of the options. Note that some output options used for a single input dataset are not available.
See also Trace Diffusion (Multi). Note that the Trace Diffusion (Multi) plugin is intended for tracing using no time gaps in the trace of a molecule, requires all input datasets to have the same time and distance calibration and will aggregate all datasets into a single superset for jump distance analysis. In contrast, the analysis performed on each dataset by Trace Molecules (Multi) is separate and there are no restrictions on matching calibration; all trace modes allow for time gaps in the trace of an individual molecule.
6.6. Trace Diffusion¶
The Trace Diffusion plugin will trace molecules through frames and then perform mean-squared displacement analysis on consecutive frames to calculate a diffusion coefficient.
The plugin is similar to the Diffusion Rate Test plugin however instead of simulating particle diffusion the plugin will use an existing results set. This allows the analysis to be applied to results from fitting single-molecule images using the Peak Fit plugin.
6.6.1. Trace Mode¶
Tracing can be performed using different trace modes:
Mode |
Description |
|---|---|
Nearest Neighbour |
Uses the nearest neighbour tracing algorithm from the |
Dynamic Multiple Target Tracing (DMTT) |
Uses the dynamic multiple target tracing algorithm from the |
Note that diffusion analysis is based in consecutive frames. If tracing allows gaps then the initial discontinuous tracks are divided into continuous tracks before diffusion analysis.
6.6.2. Analysis¶
Once the tracks have been identified any tracks containing frame gaps are split into sub-tracks with contiguous frames. Diffusion analysis with variable frame gaps is not supported. The tracks are then filtered using a length criteria and shorter tracks discarded. Optionally the tracks can be truncated to the minimum length which ensures even sampling of particles with different track lengths. The plugin computes the mean-squared distance of each point from the origin. Optionally the plugin computes the mean-squared distance of each point from every other point in the track. These internal distances increase the number of points in the analysis. Therefore if the track is not truncated the number of internal distances at a given time separation is proportional to the track length. To prevent bias in the data towards the longer tracks the average distance for each time separation is computed per track and these are used in the population statistics. Thus each track contributes only once to the mean-displacement for a set time separation.
The mean-squared distance (MSD) per molecule is calculated using two methods. The all-vs-all method uses the sum of squared distances divided by the sum of time separation between points. The value includes the all-vs-all internal distances (if selected). The adjacent method uses the average of the squared distances between adjacent frames divided by the time delta (\(\Delta t\)) between frames. The MSD values are expressed in μm2/second and can be saved to file or shown in a histogram.
The average mean-squared distances for all the traces are plotted against the time separation and a best fit line is calculated. The mean-squared distances are proportional to the diffusion coefficient (D):
where \(n\) is the number of separating frames, \(\Delta t\) is the time lag between frames, and \(\sigma\) is the localisation precision. Thus the gradient of the best fit line can be used to obtain the diffusion coefficient. Note that the plugin will compute a fit with and without an explicit intercept and pick the solution with the best fit to the data (see 6.6.7: Selecting the Best Fit). Note that an additional best fit line can be computed using a MSD correction factor (see 6.6.4: MSD Correction).
6.6.2.1. Apparent Diffusion Coefficient¶
Given that the localisations within each trace are subject to a fitting error, or precision (\(\sigma\)), the apparent diffusion coefficient (\(D^{\star}\)) can be calculated accounting for precision [Uphoff et al, 2013]:
The plugin thus computes the average precision for the localisations included in the analysis and can optionally report the apparent diffusion coefficient (\(D^{\star}\)). If the average precision is above 100nm then the plugin prompts the user to confirm the precision value.
6.6.3. Jump Distance Analysis¶
The jump distance is how far a particle moves is given time period. Analysis of a population of jump distances can be used to determine if the population contains molecules diffusing with one or more diffusion coefficients [Weimann et al, 2013]. For two dimensional Brownian motion the probability that a particle starting at the origin will be encountered within a shell of radius r and a width dr at time \(\Delta t\) is given by:
This can be expanded to a mixed population of m species where each fraction (\(f_i\)) has a diffusion coefficient \(D_i\):
For the purposes of fitting the integrated distribution can be used. For a single population this is given by:
The advantage of the integrated distribution is that specific histogram bin sizes are not required to construct the cumulative histogram from the raw data. Note that the integration holds for a mixed population of m species where each fraction (\(f_i\)) has a diffusion coefficient \(D_i\):
Weimmann et al (2013) show that fitting of the cumulative histogram of jump distances can accurately reproduce the diffusion coefficient in single molecule simulations. The performance of the method uses an indicator \(\beta\) expressed as the average distance a particle travels in the chosen time (d) divided by the average localisation precision (\(\sigma\)):
When \(\beta\) is above 6 then jump distance analysis reproduces the diffusion coefficient as accurately as MSD analysis for single populations. For mixed populations of moving and stationary particles the MSD analysis fails (it cannot determine multiple diffusion coefficients) and the jump distance analysis yields accurate values when \(\beta\) is above 6.
The Trace Diffusion plugin performs jump distance analysis using the jumps between frames that are n frames apart. The distances may be from the origin to the n th frame or may use all the available internal distances n frames apart. A cumulative histogram is produced of the jump distance. This is then fitted using a single population and then for mixed populations of j species by minimising the sum-of-squared residuals (SS) between the observed and expected curves. Alternatively the plugin can fit the jump distances directly without using a cumulative histogram. In this case the probability of each jump distance is computed using the formula for \(P(r^{2},\Delta t)\) and the combined probability (likelihood) of the data given the model is computed. The best model fit is achieved by maximising the likelihood (maximum likelihood estimation, MLE).
When fitting multiple species the fit is rejected if: (a) the relative difference between coefficients is smaller than a given factor; or (b) the minimum fraction, \(f_i\), is less than a configured level. If accepted the result must then be compared to the previous result to determine if increasing the number of parameters has improved the fit (see 6.6.7: Selecting the Best Fit).
Optimisation is performed using a fast search to maximise the score by varying each parameter in turn (Powell optimiser). In most cases this achieves convergence. However in the case that the default algorithm fails then a second algorithm is used that uses a directed random walk (CMAES optimiser). This algorithm depends on randomness and so can benefit from restarts. The plugin allows the number of restarts to be varied. For the optimisation of the sum-of-squares against the cumulative histogram a least-squares fitting algorithm (Levenberg-Marquardt or LVM optimiser) is used to improve the initial score where possible. The plugin will log messages on the success of the optimisers to the ImageJ log window. Extra information will be logged if using the Debug fitting option.
6.6.4. MSD Correction¶
This corrects for the diffusion distance lost in the first and last frames of the track due to the representation of diffusion over the entire frame as an average coordinate. A full explanation of the correction is provided in section 14: MSD Correction.
The observed MSD can be converted to the true MSD by dividing by a correction factor (F):
Where n is the number of frames over which the jump distance is measured (i.e. end - start).
When performing jump distance analysis it is not necessary to the correct each observed squared distance before fitting. Since the correction is a single scaling factor instead the computed diffusion coefficient can be adjusted by applying the correction factor after fitting. This allows the plugin to save the raw data to file and use for display on results plots.
If the MSD correction option is selected the plugin will compute the corrected diffusion coefficient as:
6.6.4.1. Fitting the Plot of MSD verses N Frames¶
When fitting the linear plot of MSD verses the number of frames the correction factor can be included. The observed MSD is composed of the actual MSD multiplied by the correction factor before being adjusted for the precision error:
This is still a linear fit with a new representation for the intercept that allows the intercept to be negative. To ensure the intercept is correctly bounded it is represented using the fit parameters and not just fit using a single constant C.
When performing the linear fit of the MSD verses jump distance plot, 3 equations are fitted and the results with the best information criterion is selected. The results of each fit are written to the ImageJ log. The following equations are fit:
Linear fit:
Linear fit with intercept:
Linear fit with MSD corrected intercept:
Note: In each model the linear gradient is proportional to the diffusion coefficient.
6.6.5. Precision Correction¶
Given that the localisations within each trace are subject to a fitting error, or precision (σ), the apparent diffusion coefficient (\(D^{\star}\)) can be calculated accounting for precision [Uphoff et al , 2013]:
If the Precision correction option is selected the plugin will subtract the precision and report the apparent diffusion coefficient (\(D^{\star}\)) from the jump distance analysis.
6.6.6. MSD and Precision Correction¶
Both the MSD correction and Precision correction can be applied to the fitted MSD to compute the corrected diffusion coefficient:
6.6.7. Selecting the Best Fit¶
The Akaike Information Criterion (AIC) is calculated for the fit using the log likelihood (ln(L)) and the number of parameters (p):
The AIC penalises additional parameters. The model with the lowest AIC is preferred. If a higher AIC is obtained then increasing the number of fitted species in the mixed population has not improved the fit and so fitting is stopped. Note that when performing maximum likelihood estimation the log likelihood is already known and is used directly to calculate the corrected AIC. When fitting the sum-of-squared residuals (\(SS_{\text{res}}\)) for the straight line MSD fit the log likelihood can be computed as:
This assumes that the residuals are distributed according to independent identical normal distributions (with zero mean). When the residuals are not identical normal distributions, such as fitting the cumulative jump distance histogram, then the adjusted coefficient of determination is used to select the best model:
where \(SS_{\text{tot}}\) is the total sum of squares, \(n\) is the number of values and \(p\) is the number of parameters.
6.6.8. Parameters¶
The plugin dialog allowing the data to be selected is shown in Figure 6.6.
Fig. 6.6 Trace Diffusion dialog¶
The plugin has the following parameters:
Parameter |
Description |
|---|---|
Input |
Specify the input results set. |
Mode |
Specify the trace mode.
The parameters for each are configured using the |
Min trace length |
The minimum length for a track (in time frames). |
Ignore ends |
Ignore the end jumps in the track. If a fluorophore activated only part way through the first frame and bleaches only part way through the last frame the end jumps represent a shorter time-span than the frame interval. These jumps can optionally be ignored. This option requires tracks to be 2 frames longer than the |
Save traces |
Save the traces to file in the |
6.6.8.1. Nearest Neighbour Parameters¶
Parameter |
Description |
|---|---|
Distance threshold |
The distance threshold for tracing. |
Distance exclusion |
The exclusion distance. If a particle is within the distance threshold but a second particle is within the exclusion distance then the trace is discarded (due to overlapping tracks). |
6.6.8.2. Dynamic Multiple Target Tracing Parameters¶
Parameter |
Description |
|---|---|
Diffusion coefficient |
The expected maximum diffusion coefficient for moving particles. Used to set an upper limit on the radius allowed to reconnect trajectories and localisations. |
Temporal window |
The window over which to build local statistics |
Local diffusion weight |
The weighting for the probability created using the local diffusion coefficient; the remaining probability uses the maximum diffusion coefficient. |
On intensity weight |
The weighting for the probability for non-blinking intensity; the remaining probability uses the probability for blinking intensity. |
Disappearance decay factor |
Controls the expected duration over which an off trajectory may reappear. Higher values will increase probability the molecule may reappear after t frames. |
Disappearance threshold |
The threshold used to deactivate a trajectory. Any trajectory that has been in the off (dark) state longer than this threshold is removed and cannot connect to new localisations. |
Disable local diffusion model |
Set to true to disable the local diffusion model. The diffusion model will only use the maximum diffusion coefficient. Can be used when particles blink frequently which results in under estimation of the local diffusion using jump distances due to missing distances. |
Disable intensity model |
Set to true to disable the intensity model. Can be used when the intensity of particles in a track is highly variable and intensity cannot be used to distinguish the track. |
Defaults |
Use this button to reset the values to the defaults as used in the original source paper (Sergé et al, 2008). |
When all the datasets have been traced the plugin presents a second dialog to configure the diffusion analysis. The following parameters can be configured:
Parameter |
Description |
|---|---|
Truncate traces |
Set to to true to only use the first N points specified by the |
Internal distances |
Compute the all-vs-all distances. Otherwise only compute distance from the origin. |
Fit length |
Fit the first N points with a linear regression. |
MSD correction |
Perform mean square distance (MSD) correction. This corrects for the diffusion distance lost in the first and last frames of the track due to the representation of diffusion over the entire frame as an average coordinate. |
Precision correction |
Correct the fitted diffusion coefficient using the average precision of the localisations. Note that uncertainty in the position of localisations (fit precision) will contribute to the displacement between localisations. This can be corrected for by subtracting \(4s^2\) from the measured squared distances with s the average precision of the localisations. |
Maximum likelihood |
Perform jump distance fitting using maximum likelihood estimation (MLE). The default is sum-of-squared residuals (SS) fitting of the cumulative histogram of jump distances. |
Weighted fitting |
Perform jump distance fitting using equal weights for each trace. This will use a weighted cumulative histogram, or compute maximum likelihood for each trace by summing weighted probabilities of each jump. This option will remove bias introduced by long traces by down weighting them; this is useful for non-moving long lived traces. |
MLE significance level |
Sets the significance level. This is used when testing the log-likelihood ratio during maximum likelihood fitting that an increase in model parameters improves the model. |
Fit restarts |
The number of restarts to attempt when fitting using the CMAES optimiser. A higher number produces and more robust fit solution since the best fit of all the restarts is selected. Note that the CMAES optimiser is only used when the default Powell optimiser fails to converge. |
Jump distance |
The distance between frames to use for jump analysis. |
Minimum difference |
The minimum relative difference (ratio) between fitted diffusion coefficients to accept the model. The difference is calculated by ranking the coefficient in descending order and then expressing successive pairs as a ratio. Models with coefficients too similar are rejected. |
Minimum fraction |
The minimum fraction of the population that each species must satisfy. Models with species fractions below this are rejected. |
Minimum N |
The minimum number of species to fit. This can be used to force fitting with a set number of species. This extra option is only available if the plugin is run with the |
Maximum N |
The maximum number of species to fit. In practice this number may not be achieved if adding more species does not improve the fit. |
Debug fitting |
Output extra information to the |
Save trace distances |
Save the traces to file. The file contains the per-molecule MSD and D* and the squared distance to the origin for each trace. |
Save raw data |
Select this to select a results directory where the raw data will be saved. This is the data that is used to produce all the histograms and output plots. |
Show histograms |
Show histograms of the trace data. If selected a second dialog is presented allowing the histograms to be chosen and the number of histogram bins to be configured. |
Show MSD error bars |
Show error bars on the MSD plot. |
Title |
A title to add to the results table. |
6.6.9. Output¶
6.6.9.1. MSD verses Time¶
The plugin will plot the mean-squared distances against the time as show in Figure 6.7. The plot shows the best fit line. If the data is not linear then the diffusion of particles may be confined, for example by cellular structures when using in vivo image data. In this case the diffusion coefficient will be underestimated.
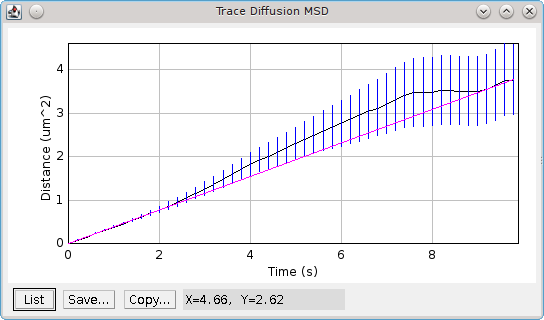
Fig. 6.7 Plot of mean-squared distance verses time produced by the Trace Diffusion plugin.¶
The mean of the raw data is plotted with bars representing standard error of the mean. The best fit line is shown in magenta.
6.6.9.2. Jump Distance Histogram¶
The plugin produces a cumulative probability histogram of the jump distance (see Figure 6.8). The best fit for a single species model will be shown in magenta. Any significant deviations of the histogram line from the single species fit are indicative of a multi-species population. If a multiple species model has a better fit than the single species model then it will be plotted in yellow.
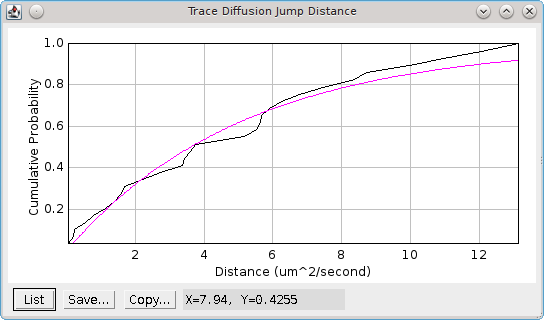
Fig. 6.8 Jump distance cumulative probability histogram.¶
The best fit for the single species model is shown in magenta.
6.6.9.3. Histograms¶
If the Show histograms option is selected the plugin presents a second dialog where the histograms can be configured. The number of bins in the histogram can be specified and outliers can optionally be removed. Outliers are any point more than 1.5 times the inter-quartile range above or below the upper and lower quartile boundaries. The following histograms can be chosen:
Parameter |
Description |
|---|---|
Total signal |
The total signal of each trace. |
Signal-per-frame |
The signal-per-frame of the localisations in a trace. |
t-On |
The on-time of a trace. This excludes the traces too short to be analysed. |
MSD/Molecule |
The average mean-squared distance per molecule. Plots of the all-vs-all and adjacent MSD are shown. If the particles contain molecules moving with different diffusion rates or a fixed fraction of molecules then the histogram may be multi-modal. |
D*/Molecule |
The apparent diffusion coefficient per molecule. Plots of the all-vs-all and adjacent D* are shown. |
Trace length |
The length of the trace in μm. |
Trace size |
The number of localisations in the trace. |
6.6.9.4. Summary Table¶
The plugin shows a summary table of the analysis results. This allows the plugin to be run with many different settings to view the effect on the calculated diffusion coefficient. The following columns are reported:
Field |
Description |
|---|---|
Title |
The title (specified by the |
Dataset |
The input dataset. |
Exposure time |
The dataset exposure time per frame. |
Trace settings |
The settings used for the trace algorithm. |
Min-length |
The minimum track length that was analysed. |
Ignore ends |
True if the end jumps of tracks were ignored. |
Truncate |
True if tracks were truncated to the min length. |
Internal |
True if internal distance were used. |
Fit length |
The number of points fitted in the linear regression. |
MSD corr |
True if MSD correction was applied. |
S corr |
True if precision correction was applied. |
MLE |
True if maximum likelihood fitting was used. |
Weighted |
True if weighted fitting was used. |
Traces |
The number of traces analysed. |
s |
The average precision of the localisations in the traces. |
D |
The diffusion coefficient from MSD linear fitting. |
Fit s |
The fitted precision when fitting an intercept in the MSD linear fit. |
Jump distance |
The time distance used for jump analysis. |
N |
The number of jumps for jump distance analysis. |
Beta |
The beta parameter which is the ratio between the mean squared distance and the localisation precision: \(\frac{\mathit{MSD}}{s^2}\). A beta above 6 indicates that jump distance analysis will produce reliable results [Weimann et al, 2013]. |
Jump D |
The diffusion coefficient(s) from jump analysis. |
Fractions |
The fractions of each population from jump analysis. |
Fit Score |
The score for the best model fit. Note that the score is not comparable between the MLE or LSQ methods for fitting. It is also not comparable when the number of jumps is different. It can only be used to compare fitting the same jump distances with a different number of mobile species. This can can be controlled using the |
Total signal |
The average total signal of each trace. |
Signal/frame |
The average signal-per-frame of the localisations in a trace. |
t-On |
The average on-time of a trace. This excludes the traces too short to be analysed. |
The plugin will report the number of traces that were excluded using the length criteria and the fitting results to the ImageJ log. This includes details of the jump analysis with the fitting results for each model and the information criterion used to assess the best model, e.g.
783 Traces filtered to 117 using minimum length 5
Linear fit (5 points) : Gradient = 2.096, D = 0.5239 um^2/s, SS = 0.047595 (2 evaluations)
Jump Distance analysis : N = 151, Time = 6 frames (0.6 seconds). Mean Distance = 1371.0 nm, Precision = 38.55 nm, Beta = 35.57
Estimated D = 0.4698 um^2/s
Fit Jump distance (N=1) : D = 0.0498 um^2/s, SS = 0.433899, IC = -453.1 (12 evaluations)
Fit Jump distance (N=2) : D = 1.655, 0.0346 um^2/s (0.1832, 0.8168), SS = 0.014680, IC = -960.3 (342 evaluations)
Fit Jump distance (N=3) : D = 1.655, 0.0346, 0.0346 um^2/s (0.1832, 0.1204, 0.6964), SS = 0.014680, IC = -956.1 (407 evaluations)
Coefficients are not different: 0.0346 / 0.0346 = 1.0
Best fit achieved using 2 populations: D = 1.655, 0.0346 um^2/s, Fractions = 0.1832, 0.8168
For use in the ImageJ macro language, extension functions can be registered that allow access to the computed diffusion coefficients and population fractions (see 11.4.1: Trace Diffusion Extensions).
6.7. Trace Diffusion (Multi)¶
This plugin allows the Trace Diffusion plugin to be run with multiple input datasets. Each dataset will be traced separately. The results are then combined for analysis. This allows analysis of multiple repeat experiments as if one single dataset.
When the plugin runs a dialog is presented that allows the datasets to be selected (Figure 6.9).
Fig. 6.9 Trace Diffusion (Multi) dataset selection dialog¶
Click a single result set to select.
Hold the
Ctrlkey and click a single result set to select or deselect.Hold the
Shiftkey to select or deselect a range of results starting from the last clicked result set.Use the
AllorNonebuttons to select or deselect all the results.Click the
Cancelbutton to end the plugin.Click the
OKbutton to run theTrace Diffusionplugin with the selected results.
When the Trace Diffusion plugin is executed it will not have the Input option as the results have already been selected. If multiple datasets are chosen the dataset name in the results table will be named using the first dataset plus the number of additional datasets, e.g. Dataset 1 + 6 others.
Note that the plugin supports the ImageJ recorder to allow running within an ImageJ macro.
See also Trace Molecules (Multi) which performs tracing on multiple datasets; each dataset is traced individually and no aggregate analysis is performed.
6.8. Track Diffusion Analysis¶
The Track Diffusion Analysis plugin extracts the diffusion distance of traced molecules over time and fits this to a diffusion model. The model accounts for diffusing molecules that exit the depth of field and are lost, avoiding underfitting of fast moving populations over time due to the lack of longer tracks for these populations. This plugin is based on the methods described in the Spot-On paper by Hansen et al (2018). The probability of a diffusing molecule remaining in the depth of field is modelled in the Diffusion Depth of Field plugin.
The plugin uses multiple input datasets that have been assigned to tracks using tracing. A traced dataset is identified using the Id field on the results from each dataset.
6.8.1. Analysis¶
The probability of a particle starting at the origin and ending at location \(r = (x, y)\) after a time delay \(\Delta t\) is given by:
where \(N\) is a normalisation constant with units of length. This is ommitted from subsequent expressions. To account for localisation error \(\sigma\) the probability is adjusted:
A multi-population state with molecules diffusing at different rates is created using a composition with the fraction of each population \(F\) multiplied by the probability of the observed distance for each respective diffusion constant. This ignores state transitions and so models the steady state of the populations.
Note that a diffusing molecule may move out of the depth of field. This can cause significant under counting of fast molecules with increasing time delay. The probability that a moving molecule will remain in the depth of field can be computed. Details of the probability model are provided in the Diffusion Depth of Field plugin. To account for molecules re-entering the depth of field a correction factor is fitted to simulated diffusion experiments. The fraction of moving molecules is thus multiplied by the probability that the molecule will remain within the depth of field \(\mathit{P}(\Delta t, \Delta z_{\text{corr}}, D)\) computed using the corrected depth of field \(\Delta z_{\text{corr}}\) based on coefficient \(a\) and \(b\) for a given depth of field \(\Delta z\), time delay \(\Delta t\) and allowed number of gaps \(g\) in the track:
The steady-state model for a 2-state population with bound fraction \(F_1\) and diffusion coefficients \(D_1\) and \(D_2\) is:
The steady-state model for a 3-state population with bound fraction \(F_1\), slow diffusing fraction \(F_2\), and diffusion coefficients \(D_1\), \(D_2\) and \(D_3\) is:
The probability model can be fit using the observed distances from tracks using different time delays, for example delays of 1 to 5 frames. The observations can be fit against a numerical integration of the probabilty model over suitable bin sizes using either maximum likelihood estimation (MLE) or least squares fitting.
If the number of observed distances is low then fitting may be unreliable. A simulation can be performed to generate data for a set number of molecules. This can be used to determine how many tracks are required for a reliable fit to an expected population with specified diffusion coefficients.
The number of observed distances can be increased by using successive frames from the start of the track as the origin, for example an offset of 1 will compute distances from the track using the second localisation as the origin. This will increase the number of observed distances but will lead to under representation of long distances at large time delays.
6.8.2. Parameters¶
The following parameters can be set:
Parameter |
Description |
|---|---|
Depth of field |
The depth of field. |
Max t |
The maximum time step \(-\Delta t\) to use for diffusion distances (in frames). |
Offsets |
The number of offsets to use for the origin of the track. Each offset will incease the count of diffusion distances but may lead to under representation of long distances at large time delays. |
Precision |
The localisation precision. This can be fixed, or a fitted parameter. |
Fit mode |
The mode used for fitting. |
Bin width |
The bin width for the histogram counts used to create the observed PDF. Used for plot display and optional fitting. |
CDF bin width |
The bin width for the histogram counts used to create the observed CDF. Used for optional plot display and fitting. Must be equal or below the bin width for the PDF if it is used as this is for a higher resolution distribution of the data. |
A |
The depth-of-field correction coefficient a (see Diffusion Depth of Field plugin). |
B |
The depth-of-field correction coefficient b (see Diffusion Depth of Field plugin). |
Optimiser mode |
The optimiser to use for fitting. |
Repeats |
The number of repeats for fitting. Each repeat uses a random initialisation for the parameters; multiple repeats can avoid choosing a local minima for the final result. |
Min D |
The minimum diffusion coefficient to use when initialising the mobile population. If the three-state model is used the slow fraction will initialise using the lower third of the range and the fast fraction the upper third of the range ([min D, max D]). |
Max D |
The maximum diffusion coefficient to use when initialising the mobile population. |
Fit precision |
If |
Fit three state |
If |
Significance level |
The significance level for the log-likelihood ratio test. |
Show CDF |
If |
Separate plots |
If |
Plot max r |
The initial limit for the maximum distance on the plot x-axis. Set to zero to ignore and use the full data limit. Note the plot can be rescaled after display to show the entire range of data with the plot |
6.8.3. Output¶
The analysis will record progress to the ImageJ log window:
The total number of distances for each time delay.
The fit result for each repeat.
The result of the significance test comparing the two-state and three-state model.
Note that the choice of the three-state model should also consider the biological rational for the fitted parameters. For example a population fraction may be too small; the diffusion coefficients for the two mobile populations are effectively the same; or a diffusion coefficient is too fast.
The observed PDF and the fit are plotted for each time delay (Figure 6.10). This may optionally be separated into a plot for each time delay.
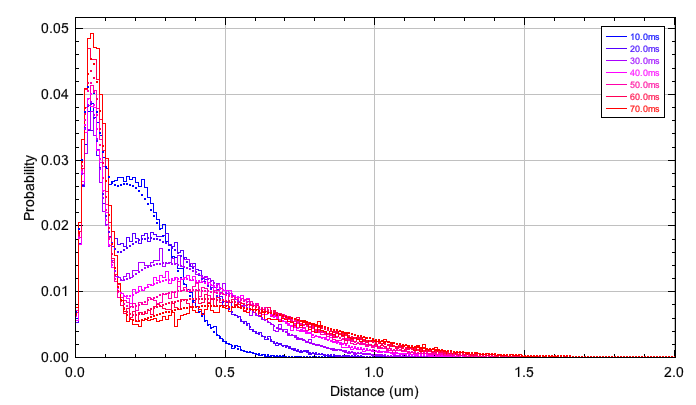
Fig. 6.10 Observed and fitted PDF of diffusion distances¶
A summary table is shown containing the model parameters. The following columns are reported:
Field |
Description |
|---|---|
Dataset |
The title of the input data. |
dz |
The depth of field. |
dt |
The exposure time. This is the time delay for 1 frame. |
Max t |
The maximum time step \(-\Delta t\) to use for diffusion distances (in frames). |
Offsets |
The number of offsets to use for the origin of the track. |
A |
The depth-of-field correction coefficient a. |
B |
The depth-of-field correction coefficient b. |
Optimiser |
The optimiser used for fitting. |
Repeats |
The number of repeats for fitting. |
Min D |
The minimum diffusion coefficient to use when initialising the mobile population. |
Max D |
The maximum diffusion coefficient to use when initialising the mobile population. |
F |
The fitted fractions for the population. |
D |
The fitted diffusion coefficients for the population. |
sigma |
The localisation precision (either fitted or fixed). |
Value |
The fit value, either the sum-of-squares or the log-likelihood. |
6.8.4. Simulation¶
If the Shift key is held when executing the plugin then a simulation of molecule diffusion is performed. A configured number of molecules are uniformly placed through the depth of field \([-\Delta z, \Delta z]\). Molecules are randomly allocated a specified diffusion coefficient based of the fractions of each population. Three dimensional Brownian diffusion is simulated for a configured number of time steps. If the molecule exits the depth of field it may re-enter within the given gap distance, otherwise it can start a new track. The simulated tracks are saved to memory. These are idealised tracks with perfect tracing of molecules (no trace distance). The localisations may be retraced using the Trace Diffusion plugin.
The following parameters can be set:
Parameter |
Description |
|---|---|
Depth of field |
The depth of field. |
Exposure time |
The time step (exposure time) for each frame. |
Gap |
The maximum allowed time gap between localisations in a track. Use 1 for continuous tracks. Greater than 1 allows a molecule to leave the depth of field and re-enter. |
Number of molecules |
The number of molecules in the simulation. |
Max t |
The maximum number of frames in the simulation. |
Use detector |
If |
Detector curve |
A file containing a detector curve. The file has lines containing the z depth (in nm) and the detection probability. The fields can be delimited by tab, space, or comma. The curve is interpolated using a cubic spline. |
Allow restarts |
If |
Half-life |
The molecule half-life. This is required when using |
Precision |
The localisation error added to the recorded x and y coordinates. |
F1 |
The fraction of the population with diffusion coefficient D1. |
F2 |
The fraction of the population with diffusion coefficient D2. If set to zero then F2 = 1 - F1 for a two-state simulation. If above zero then F3 = 1 - F1 - F2 for a three-state simulation. |
D1 |
The diffusion coefficient for the first class of molecules. |
D2 |
The diffusion coefficient for the second class of molecules. |
D3 |
The diffusion coefficient for the third class of molecules. |
The simulation allows experimenting with the number of samples required to obtain satisfactory results for the fitting of observed diffusion distance distributions.
6.9. Trace Length Analysis¶
Analyses the track length of traced data and optionally provides an interactive method to split a dual population of fixed and moving molecules.
Allows the traced dataset to be selected. The traced data is then analysed to compute the length of each trace in frames and the mean squared displacement (MSD). The MSD is the mean of the sum of the squared jump distances between localisations in the trace. Each jump distance has the localisation precision subtracted from the jump length (i.e. the expected error in the measurement). The MSD can be converted to the diffusion coefficient for 2D diffusion:
The Trace Length Analysis plugin shows two histograms:
Histogram |
Description |
|---|---|
Trace diffusion coefficient D |
The computed diffusion coefficient for all traces. |
Trace length distribution |
The distribution of trace lengths for the fixed and moving molecules. |
An interactive dialog is shown that allows the traces to be split into fixed and moving molecules. The following parameters can be set:
Parameter |
Description |
|---|---|
D threshold |
The threshold for the diffusion coefficient to split molecules into fixed and moving populations. |
Normalise |
If true the |
If the Save datasets button is pressed the input dataset will be saved to memory as two datasets with the Fixed and Moving suffix based on the current diffusion coefficient threshold.
Note: An ideal dual population of fixed and moving molecules will be a bimodel histogram of the diffusion coefficient, for example DNA binding proteins that are either diffusing freely or bound to the DNA. If this plugin is run on data which does not contain an obvious dual population of fixed and moving molecules then the histogram will be unimodal. If the population contains only moving molecules then the diffusion coefficients will have a mode far above zero. If the population contains only fixed molecules then the diffusion coefficients will be very low with a mode close to zero. A split of mixed populations of diffusing molecules with different diffusion coefficients is not supported.
6.10. Track Population Analysis¶
The Track Population Analysis plugin runs on one or more datasets stored in memory that contain track IDs. All contiguous localisations from each track are extracted into a dataset of sub-tracks. A sliding window (of size \(w\)) is used over each sub-track to extract local features describing the diffusion of the molecule. The time step \(\Delta t\) is the frame exposure time. Each time point in each sub-track is described using a feature vector.
The plugin will detect if the input localisations have been assigned a category. If present the category can optionally be used to identify sub-populations within the tracks. Alternatively a multivariate Gaussian mixture model is fit to the data using the Expectation-Maximisation algorithm to estimate sub-populations of tracks that have different diffusion characteristics, for example a stationary and a moving population of molecules.
6.10.1. Anomalous exponent¶
The anomalous exponent is obtained from fitting the mean squared distance (MSD) curve. The MSD is computed for each jump distance (\(n\)) within the window:
for \(n \in [1, \dots, w-1]\) and \(i \in [0, \dots, w-n-1]\). The MSD is fit using various models. The case of standard diffusion is fit using a linear model for standard Brownian motion diffusion [Backlund, et al (2015), eq. 1]:
where \(D\) is the diffusion coefficient and \(s\) is the static localisation precision.
The case of anomalous diffusion is fit using a fractional Brownian motion (FBM) diffusion function [Backlund, et al (2015), eq. 8]:
where \(\alpha\) is the anomalous diffusion coefficient. A value of 1 denotes standard Brownian motion, \(\alpha > 1\) is super-diffusion (containing elements of deterministic directed motion) and \(\alpha < 1\) is sub-diffusive motion.
The Brownian model is a nested model of the FBM model. The significance of the FBM model can be computed using an F-test on the residual sum of squares. The number of insignificant fits is reported to the ImageJ log window. When the number of insignificant fits is high then the data may contain only standard Brownian motion and the anomalous coefficient \(\alpha\) can be ignored during the population analysis.
Note: The fit assumes an increasing MSD with time. If a flat or negative slope occurs for the MSD then the data likely corresponds to a stationary molecule, or a moving molecule that transitioned to stationary within the analysis window. In this case the anomalous coefficient is meaningless and a value of 1 is used.
6.10.2. Effective diffusion coefficient¶
The effective diffusion coefficient is computed using the empirical estimator [Hozé, 2017, eq 10]:
This is the average squared distance between successive localisations within the analysis window.
6.10.3. Length of confinement¶
The length of confinement is computed using the standard deviation of the position of the localisations within the window. The standard deviation in dimensions X and Y are averaged to create the length of confinement. Note the standard deviation in a single dimension for a stationary molecule is equivalent to the static localisation precision.
6.10.4. Drift vector magnitude¶
The drift vector is computed as the expected distance between successive points in each dimension, i.e. the average step size [Hozé, 2017, eq 9]. This analysis uses the Euclidean norm of the drift vector to characterise the magnitude of the displacement.
6.10.5. Gaussian Mixture Model¶
The features of each point are modelled as a dimension in a multi-variate Gaussian distribution. The population may be composed of different types of diffusing molecules; each sub-population will have a different multi-variate Gaussian distribution and the components are combined in a weighted mixture. The Expectation-Maximisation (EM) algorithm is used to fit a mixture multi-variate Gaussian distribution to the data using an increasing number of components. The likelihood of the fit is compared to the previous model to determine if the increase in the number of components is significant. This is done using an Akaike Information Criterion (AIC), Bayesian Information Criterion (BIC) and a log-likelihood ratio test. If these show no significant improvement then the fit is rejected. The fit can also be rejected if the weight of one of the sub-populations in the mixture is below a threshold.
Fitting the model using the EM algorithm requires an initial seed model. Convergence may not be possible from a given seed and the result may not achieve the maximum likelihood. The plugin provides the option to configure the random seed, the number of initial models and the convergence criteria for the algorithm. The results of each fit can be logged to the ImageJ log window; the best model is used for analysis.
6.10.6. Parameters¶
When the plugin runs a dialog is shown containing all the localisation datasets in memory that contain track IDs. The user can select one or more datasets for analysis. The plugin will verify that the exposure time and spatial calibration are the same across all datasets. This ensures analysis of the same sliding window across datasets is comparable.
If the input data contains categories in the localisations the plugin will ask if these should be used as the populations. This enables track populations to be assigned using external analysis and the results loaded for display. If Yes is selected then the options for fitting the multivariate Gaussian mixture are not shown in the parameter input dialog.
The following analysis parameters can be configured:
Parameter |
Description |
|---|---|
Window |
The window size used to create the local diffusion features. Must be at least 5 to satisfy the fit of the MSD. |
Min track length |
The minimum length of consecutive windows to include a track (must be at least 1). Note: This does not refer to the original track length but to the length of the track where local features can be computed. The minimum number of localisations in an original diffusion track is the window size plus the minimum track length minus 1. |
Fit significance |
The level to use in the F-test to determine if the significance of the fit of the anomalous diffusion coefficient alpha (compared to the standard Brownian diffusion model). The significance level is used to record insignificant fits to the |
Min alpha |
The minimum anomalous diffusion coefficient alpha to allow during fitting. |
Max alpha |
The maximum anomalous diffusion coefficient alpha to allow during fitting. |
Ignore alpha |
Set to true to ignore the anomalous diffusion coefficient alpha in the multivariate Gaussian. Use this setting when the populations are expected to follow standard Brownian diffusion or fitting of the alpha produces many insignificant fits. |
Max components |
The maximum number of components in the multivariate Gaussian mixture. Fitting will incrementally increase the number of components until additions do not significantly increase the likelihood score of the population. |
Min weight |
The minimum weight for a component in the multivariate Gaussian mixture. If the Expectation-Maximisation algorithm generates a mixture with a component weight less than this fraction then the mixture will be rejected. |
Max iterations |
The maximum number of iterations of the Expectation-Maximisation algorithm. |
Relative error |
The relative error for the likelihood score for convergence in the Expectation-Maximisation algorithm. |
Repeats |
The number of initial mixtures to use for the Expectation-Maximisation algorithm. |
Seed |
The random seed to use to create the initial mixtures for the Expectation-Maximisation algorithm. |
Debug |
Set to true to log additional information during the analysis. |
Histogram bins |
The number of bins to use in the histogram. Set to zero for automatic bin size based on the data. |
LUT |
The look-up table used to colour the different components of the population mixture. This is used on the plot outputs and the track image output. |
6.10.7. Results¶
The plugin will extract all the contiguous tracks from all the input datasets that satisfy the length criteria. The number of tracks and their average length are recorded to the ImageJ log window. For each track the diffusion features are computed. The count of insignificant anomalous diffusion coefficients is recorded in the ImageJ log window. This can be used to assess if the alpha coefficient should be ignored when fitting a mixture multivariate Gaussian model to the data. For reference an unmixed (1 component) model is created and the log-likelihood recorded. The number of components is increased up to the Max components limit until either the Expectation-Maximisation algorithm fails to converge, the new model is not significant or the mixture contains a fraction below the configured Min weight level. At each increase in number of components the log-likelihood of the model is recorded to the ImageJ log window.
The model is used to classify each data point into a component. The data point is assigned to the component with the highest weighted probability from the mixture. A smoothing window of size 3 is used on the initial assignments to eliminate isolated assignments. If an assignment’s two immediate neighbours are the same class and different from the assignment then the point is reassigned using the neighbour class. The number of re-labelled assignments is reported to the ImageJ log window.
The population parameters of the final multivariate Gaussian mixture model are recorded in a results table. The components are ordered by the mean of their effective diffusion coefficient.
A histogram is created for each of the local diffusion features. Black bars represent the single population. Coloured bars represent each component. The colour is specified using the LUT parameter.
A table is presented summarising the track data. This lists the track length, the number of components in the track and the number of transitions between components (diffusion states). The table is interactive. Clicking a track in the table will create:
A plot of the weighted probability for each component against the track length.
Plots of each local diffusion feature against the track length. The plots are coloured using the component class assigned to the time point.
A plot of the effective diffusion coefficient from single jumps (i.e. diffusion without the averaging of the sliding window). This is not used in the feature analysis to classify components.
An image of the track. The pixel size of the image can be specified in the table options. This is enlarged by magnifying the image until the long edge of the image window is above a pixel size threshold. The track is coloured using the component class for the time point. The unclassified time points in the track, before/after the extent of the sliding window, are shown in dashed lines using light/dark grey for the start/end points respectively. The final localisation is shown using a circle.
Display of the track data can be configured using Options > Track Data... menu in the track data table. This will display the first track if multiple tracks are selected.
The table allows selection of multiple tracks to perform analysis. If more than one track is selected then analysis will target the selected tracks. Otherwise analysis will use the entire set of tracks.
The track data can be saved to a dataset using the Data > Save... menu in the track data table. This supports saving the currently selected tracks or the entire set of tracks.
Display of the jump distances used to fit the anomalous exponent can be viewed using Analysis > Anomalous exponent view menu in the track data table. This will present a dialog for the currently selected track where the data window can be selected; this corresponds to a contiguous set of localisations of the configured analysis window size. The mean squared jump distances for each time gap in the analysis window are extracted and the fit of the standard Brownian model and the fractional Brownian motion (FBM) model are shown. Optionally the plot can be changed to divide the MSD by the time and use a log scale for visualisation; the fitting is unaffected. Assuming a simple exponential equation for the MSD the plot of MSD/t verses time is a straight line where the gradient is the anomalous exponent minus 1:
Thus this visualisation can be used to see if the data trend for the gradient is positive (\(\alpha > 1\)), negative (\(\alpha < 1\)), or no gradient (\(\alpha = 1\)). Note that this is a simplification of the true MSD equations for visual reference only. The plotted lines represent the fitted MSD equations and a negative gradient line can be produced for \(\alpha = 1\). This is easy to see by toggling the plot from MSD vs t to MSD/t vs t.
Display of the jump angles for each component can be viewed using Analysis > Jump angles menu in the track data table. This will compute the angle between consecutive jumps as the angle between the vectors p1 to p2 and p2 to p3. A minimum distance for the two vectors can be specified. This should be set above the localisation precision to exclude computing angles between jumps that are subject to localisation error. The number of angles excluded is reported to the ImageJ log window and may totally exclude components that are stationary or very slowly diffusing from analysis. Angles are computed in the range 0 to 360 where an angle of 0 is the exact same direction; an angle of 180 is a complete reversal of the direction. A histogram is presented of the jump angles using 15 degree bins and the asymmetry coefficient is computed using the ratio of forward (fwd) and backward (bwd) jumps computed using the angles within 30 degrees of the forward or backward directions [Izeddin et al, 2014]:
A value above zero indicates more forward jumps, and below zero is more backward jumps (confined diffusion).
Fitting of the jump distances for each component can be performed using Analysis > Fit jump distances menu in the track data table. Continuous regions of the same component class with a length at least as long as the analysis window are used (these are identified as sub-tracks). All jump distances from 1 frame up to the window length are computed for the sub-track and a least squares fit of the entire dataset is performed. The MSD verses Time plot is shown for each component. Optionally this can be changed to divide the MSD by the time. Error bars show the standard error of the MSD. The number of sub-tracks, the number of full window jumps (N) and the degrees of freedom (DF) of the FBM model (number of jump distances minus 3) are shown in the plot label. The parameters for the Brownian and FBM models are shown in the label with the p-value indicating the likelihood of the FBM model result occurring by chance. Diffusion coefficients (D) are in μm2/s and localisation precision (s) is in μm.
Note: The population model contains an average of the anomalous diffusion coefficients for each window in the population. These individual values are produced from fitting a low number of jumps, the windows may contain localisations in different component classes (e.g. a moving molecule transitioning to a fixed molecule) which invalidates the fitted model, and the FBM model may not be significant. In addition averages will use windows that overlap each other therefore using duplicate jumps. Thus average diffusion coefficients may not be comparable to the fit of the entire set of jump distances for each component.
The residence times for the length of time spent in each component can be displayed using Analysis > Residence times. This will create a histogram and observed cumulative distribution function of the residence times. The length of time for the component at the start and end of the track is ignored so that the data only contains lengths with a defined start and end. The data is thus generated only for tracks with at least 2 transitions between component states. The observations are fit assuming an exponential distribution where \(T_R\) is the mean residence time:
The histograms are overlaid with the fitted exponential function. Bootstrapping is used on the data to produce a 95% confidence interval for the mean residence time.
6.11. Residence Time Analysis¶
The Residence Time Analysis plugin runs on one or more datasets stored in memory that contain track IDs. All localisations from each track are extracted into a dataset of tracks. The tracks are filtered to non-diffusing particles. The residence times of the bound particles are analysed to identify the dissociation rate.
Note that it is possible to image bound molecules at a low frame rate such that any freely diffusing molecules are blurred by their motion and only immobile molecules will be observed. However a low frame rate reduces the resolution of the residence time histogram. Instead the molecules can be imaged at a higher frame rate which will include freely diffusing molecules. These can be filtered using their larger jump distances. The remaining bound molecules residence times will have a higher resolution which enables better fitting of the dissociation rate. Very high frame rates may not be possible due to the increased illumination required to image the localisations and the effect of photo-bleaching.
The residence time is fit using the survival function for an exponential model (this is the complementary cumulative distribution function) with weights for the population fractions:
where \(k_i\) is the dissociation rate for the population and the sum of the weights is 1. Fitting supports a 1, 2 or 3 population model. The 1 population model assumes all bound molecules are in the same state. The multi population models assume that bound molecules have multiple states, and each state has a different dissociation rate. For example specific binding and non-specific binding may have a slower dissociation rate for the specific binding as the molecule is used to perform a function; if non-specific binding occurs then the molecule will dissociate faster as it has no function to perform.
The residence time t is not continuous as the data contain residence times in frames. Maximum likelihood fitting is performed by assigning observations a probability using the difference of the survival function at the start and end of the frame time, e.g. the duration of frame \(f\) uses \(P(f) = P(T >= f \Delta t) - P(T >= (f+1) \Delta t)\) where \(\Delta t\) is the frame exposure time.
The observed dissociation rate \(k_{obs}\) is a combination of the binding dissociation rate \(k_b\) and the apparent dissociation rate \(k_a\) due to technical imaging limitations such as photo-bleaching and diffusion of the bound complex. The observed rate is a combination of these two exponential processes:
The plugin allows the apparent dissociation rate to be entered and the mean residence time is computed as:
The apparent dissociation rate can be obtained from control experiments using molecules known to be non-transiently bound, for example using histone proteins bound to chromosomal DNA.
When the plugin runs a dialog is presented that allows multiple datasets to be selected. All datasets must have the same calibration for exposure time and pixel size. A second dialog is then displayed to configure the analysis options. The following parameters can be set:
Parameter |
Description |
|---|---|
First frame |
Used to remove traces start at or before the first frame. Set to zero to disable. |
Last frame |
Used to remove traces end at or after the last frame. If negative the actual last frame |
Min size |
The minimum number of localisations in a track. Use this to exclude single localisations or short tracks. The residence time histogram is computed using the track duration beyond this minimum threshold. |
Mean distance |
The maximum allowed mean distance between neighbouring localisations of a track. This should be set using a value approximately above the localisation precision (assuming non-diffusing molecules). If the molecules are slowly diffusing in their bound phase then this threshold should be raised. |
Max distance |
The maximum allowed distance between neighbouring localisations of a track. Use this to filter tracks where the molecule jumps location between successive time points. |
Max populations |
The maximum number of populations to fit. The best model should be chosen based on the log-likelihood based information criterion and the population parameters. Populations that have multiple fractions with a similar residence time should be ignored. |
Max trace length |
The maximum length of tracks. Used to truncate the residence time histogram. |
Min bin count |
The minimum histogram bin count. The tail of the histogram is truncated to the first bin above this threshold. |
Apparent residence time |
The apparent residence time (due to imaging limitations). Used to correct the observed residence time. |
Bootstrap repeats |
The number of bootstrap repeats used to create a 95% confidence interval. |
Bootstrap seed |
Random seed for the bootstrap repeats (hexidecimal input). |
Show QQ plot |
Display a quantile-quantile plot of the model against the data distribution. The quantile for the model is taken using the cumulative probability of the data as (k - 1/3) / (n + 1/3). |
Debug |
If enabled extra information is logged to the |
The analysis extracts the tracks and filters them to stationary molecules. A histogram of residence times is created and fit using the exponential model (see Figure 6.11). Fit progress is recorded in the ImageJ log window. Bootstrapping is optionally used on the data to produce a 95% confidence interval for the fit parameters.
Fig. 6.11 Residence time histogram.¶
The histogram was simulated using n = 5000; k0 = 0.2/sec; k1 = 5.0/sec; f0 = 0.15; exposure time = 50ms. The histogram is overlaid with the 1 and 2 population model.
A summary table is shown containing the model parameters. The following columns are reported:
Field |
Description |
|---|---|
Title |
The title of the input data. |
Samples |
The number of samples in the residence time histogram. Corresponds to the number of stationary molecules. |
Time |
The frame exposure time. |
n |
The number of populations in the model. |
k |
The dissociation rate for each population in the model. |
CI |
The 95% confidence interval for each dissociation rate. |
fraction |
The population weight. |
CI |
The 95% confidence interval for each fraction. |
ka |
The user-provided apparent residence time (used to correct the observed residence time). |
Residence time |
The corrected mean residence time for each population in the model. |
CI |
The 95% confidence interval for each residence time. |
LL |
The log-likelihood of the model (higher is better). |
AIC |
The Akaike information criterion (AIC) for the model. This adjusts the log-likelihood score using the number of fitted parameters (lower is better). |
BIC |
The Bayesian information criterion (BIC) for the model. This adjusts the log-likelihood score using the number of fitted parameters and sample size (lower is better). The BIC generally penalises free parameters more strongly than the AIC. |
6.11.1. Simulation¶
If the Shift key is held when executing the plugin then a simulation of residence times is performed. This will not require input localisation data and directly creates a residence time histogram.
The following parameters can be set:
Parameter |
Description |
|---|---|
Seed |
Random seed for the simulation (hexidecimal input). |
Samples |
The number of samples. |
k0 |
The dissociation rate for the first population. |
k1 |
The dissociation rate for the second population. |
f0 |
The fraction for the first population. Must be in the range (0, 1]. Set to 1 to have a single population. |
Exposure time |
The frame exposure time. |
Max populations |
The maximum number of populations to fit. The best model should be chosen based on the log-likelihood based information criterion and the population parameters. Populations that have multiple fractions with a similar residence time should be ignored. |
Max trace length |
The maximum length of tracks. Used to truncate the residence time histogram. |
Min bin count |
The minimum histogram bin count. The tail of the histogram is truncated to the first bin above this threshold. |
Bootstrap repeats |
The number of bootstrap repeats used to create a 95% confidence interval. |
Bootstrap seed |
Random seed for the bootstrap repeats (hexidecimal input). |
Show QQ plot |
Display a quantile-quantile plot of the model against the data distribution. The quantile for the model is taken using the cumulative probability of the data as (k - 1/3) / (n + 1/3). |
Debug |
If enabled extra information is logged to the |
The simulation allows experimenting with the exposure time and number of samples required to obtain satisfactory results for the populations of bound molecules.
6.12. OPTICS¶
Runs the Ordering Points To Identify the Clustering Structure (OPTICS) algorithm [Ankerst et al, 1999] to perform interactive density-based clustering of localisation data. Each point in the data is analysed to determine the number of neighbours within a specified radius. A minimum number of points (MinPoints) is specified which describes the number of points required to form a cluster. If the MinPoints is achieved for the point neighbourhood the algorithm assigns each point the core distance which is the distance to the MinPointsth closest point. The reachability-distance of another point p2 from point p1 is the maximum of the distance between them or the core distance. If point p2 is above the maximum radius to consider then there is no reachability distance.
Processing starts from an arbitrary unprocessed point. The neighbours are computed as points within the radius. If the neighbourhood satisfies MinPoints then a new cluster is created. The neighbours are added to a sorted queue to be processed. Processing occurs in order of their reachability-distance. During processing the reachability distance of points already in the queue may change (reduce in size) and the queue is reordered. When no more points are reachable from the cluster then a new unprocessed point is chosen.
The OPTICS algorithm requires parameters radius and MinPoints. The run-time of the algorithm depends on radius. If set to the maximum distance between any two points in the data then the run-time is asymptomatically quadratic as each neighbourhood returns all the points. The MinPoints parameter is recommended to be double the number of dimensions: for 2D localisation data that is 4.
FastOPTICS is a variant that is not parameterised using a neighbour radius. The algorithm is based on the concept that a pair of points close in N-dimensional space are also close when the space is projected to 2D. The algorithm computes a number of projections of the data onto a line. This line can be randomly orientated or orientated using equi-distributed vectors around a circle. Each projection provides a linear order of points along the line using a distance from the origin. This set of points is recursively split using random divisions until subsets are all below MinPoints in size. The points in a subset are allocated as neighbours of a chosen point in the subset. The point is chosen either randomly, as the median of the subset (using the distance from the origin) or all points are chosen. After a number of random projections each point has an allocated neighbourhood of points. The rest of the algorithm functions the same as OPTICS but with pre-computed neighbours and no requirement for a radius.
The OPTICS algorithm outputs the points in a particular ordering. A plot of the order against the reachability distance shows a dendrogram-like structure where the clusters show as wells in the reachability profile. OPTICS provides an algorithm that analyses the gradient of the profile in runs of up and down and uses this to assign a hierarchical level of clustering to the data based on a parameter Xi (the change in reachability to define a cluster). A second clustering algorithm uses a fixed distance threshold. All adjacent points in the profile that are reachable below this distance are assigned to the same cluster. The result is the same as if using the DBSCAN algorithm (see section 6.13).
A local outlier probability (LoOP [Kriegel et al, 2009]) analysis can be performed by the plugin. The local density is estimated by the typical distance at which a point can be “reached” from its neighbours specified using the MinPoints nearest neighbour. By comparing the local density of an object to the local densities of its neighbours, one can identify regions of similar density, and points that have a substantially lower density than their neighbours. These are considered to be outliers. LoOP analysis produces a score in the range of 0 to 1.
The OPTICS plugin has a preview mode that allows the parameters to be changed and the results updated in real-time. There are various output options to control outlining of clusters on an image, viewing of the clustering structure on the reachability profile and tabulation of cluster results. The OPTICS dialog is non-blocking allowing the other ImageJ windows to be used when the preview is active.
6.12.1. Parameters¶
The following options are available (extra options are activated by holding the Shift when running the plugin):
Parameter |
Description |
|---|---|
Input |
Select the input results to analyse. |
Ignore Z |
Set to true to ignore the z coordinate in 3D data and perform 2D clustering. The default is 3D clustering for 3D datasets. Note: The visualisation of clustering results is optimised for 2D. For 3D data the results will be viewed using a projection onto the XY plane. |
Min points |
The minimum number of neighbours required to create a cluster. |
OPTICS mode |
The mode to find neighbours:
|
Clustering |
Specify the algorithm to assign clusters:
The |
Show table |
Show the clusters in a results table. The sort order for the table data can be configured. |
Image scale |
Specify the scale for the output image. The size of the image is the raw pixel bounds for the localisation data multiplied by the scale. |
Image mode |
Specify the mode used to colour the image localisations.
The |
Outline |
Specify how clusters should be outlined on the image. The outline algorithm can be configured using the Outlines can be optionally saved to the The concave hull can use the K-nearest neighbour method of Moreira and Santos (2007), or the digging algorithm of Park and Oh (2012). For the digging algorithm the threshold is the allowed ratio between the edge distance and the distance to the internal point; a higher threshold results in a less concave hull. |
Spanning tree |
Specify how links between localisations should be outlined on the image. Links represent the connections made between points as they were included in the cluster following the imposed OPTICS order. The links create a spanning tree and can be coloured by coloured by cluster ID; depth in the clustering hierarchy; OPTICS order; or the LoOP (local outlier probability) score. |
Plot mode |
Configure the options for the reachability profile plot. The profile represents the reachability of each localisation in the order imposed by the OPTICS algorithm. Clusters represent a span on the profile. The plot can be drawn with just the profile or with lines underneath the profile representing cluster spans. Hierarchical clusters are shown at their corresponding depth level. Clusters are coloured using a look-up table that attempts to achieve maximum distinction between different colours; the colours themselves are not significant. The reachability can be highlighted for all points in a cluster or each cluster can be drawn using either cluster ID, depth or order. In the case of multiple clusters at the same point the colour of the deepest cluster takes precedent. |
Preview |
Enables the live preview of results. Settings changes will result in live update of the displayed results. The
Note: It is possible that the live preview can stop responding to click events, e.g. on the localisation image or cluster table. In this case simply disable and re-enable the preview. |
Debug |
Extra option: If true write debugging information to the Java console. |
6.12.2. Analysis¶
The OPTICS plugin records processing details to the ImageJ log window. This includes:
The settings for FastOPTICS including the number of splits and projections performed.
The processing time for the algorithm which may include splitting the data, computing neighbourhoods and the number of distance comparisons computed. This can be used to performance tune the parameters if the processing is taking too long.
The number of clusters if the
Pseudo-DBSCANclustering method is run on the profile with an estimated generating distance. The estimated distance is created using the radius of the circle required to contain theMin pointsof neighbours assuming the localisations are uniformly spread over the region defined by the X/Y bounds.
If the live preview is active the plugin also records the Rand index comparing the current clustering with the previous clustering. This provides an indication of how much the clustering has changed with settings changes.
6.12.3. Results¶
The OPTICS plugin will create results displayed in windows. If the OK button is pressed the final settings will be used to update any live preview results. If live preview was not enabled then the results will be displayed. Note that the selection events are only created and handled when the OPTICS plugin dialog is open. After the dialog has been closed the results windows are no longer interactive.
OPTICS will save the clustering results to a dataset in memory. Localisations will have an ID assigned if they were part of a cluster. The ID will be from the cluster in the deepest part of the hierarchy.
An example of the reachability profile is shown in Figure 6.12. Notes:
The profile may be very large as all localisations will be represented along the horizontal axis.
An image can be zoomed to a region in
ImageJby using the ROI tool to mark a region and then pressing+or usingMore >> Zoom to Selection.The axes can be reset using
More >> Set Range to Fit All.The plot window can be resized by dragging the window frame edges / corners.
Fig. 6.12 OPTICS reachability profile.¶
The profile is coloured using the cluster depth and the hierarchical clusters are displayed underneath the profile.
Examples of the clusters and spanning tree overlaid on an image are shown in Figure 6.13 and Figure 6.14. Notes:
The image can be zoomed using the
+and-keys.Holding the
Spacebar allows the canvas to be scrolled using mouse drag.

Fig. 6.13 OPTICS clusters outline.¶
The outline, representing the convex hull of clusters, is coloured using the cluster depth and overlaid on a super-resolution image of the localisations.

Fig. 6.14 OPTICS clusters spanning tree.¶
The spanning tree, representing the OPTICS order used to connect localisations, is coloured using the cluster depth and overlaid on a super-resolution image of the localisations.
6.13. DBSCAN¶
Runs the Density-based spatial clustering of applications with noise (DBSCAN) algorithm [Ester et al, 1996] to perform interactive density-based clustering of localisation data.
This plugin is a modification of the OPTICS plugin. The DBSCAN algorithm predates the OPTICS algorithm. The difference is that localisations are processed in arbitrary order. In OPTICS the algorithm tracks how reachable points are from each other and links more reachable points first. DBSCAN does not make this distinction. As per OPTICS the DBSCAN algorithm analyses each point in the data to determine the number of neighbours within a specified radius. A minimum number of points (MinPoints) is specified which describes the number of points required to form a cluster.
Processing starts from an arbitrary unprocessed point. The neighbours are computed as points within the radius. If the neighbourhood satisfies MinPoints (defined as a core point) then a new cluster is created. The neighbours that are reachable from a core point are added to the cluster and put in a queue to be processed. Processing occurs in arbitrary order. When no more points are reachable from core points in the cluster then a new unprocessed point is chosen.
The DBSCAN algorithm requires parameters radius and MinPoints. The run-time of the algorithm depends on radius. If set to the maximum distance between any two points in the data then the run-time is asymptomatically quadratic as each neighbourhood returns all the points. The MinPoints parameter is recommended to be double the number of dimensions: for 2D localisation data that is 4.
If points can be reached within the clustering distance from any core point then they are included in the cluster. Clusters are not hierarchical. The algorithm is faster than OPTICS due to the arbitrary processing order. OPTICS is approximately 1.6x slower.
6.13.1. Parameter Estimation¶
The MinPoints parameter can be set to approximately 2 times the number of dimensions. For 2D localisation data this is 4. It may be necessary to increase this number for large datasets, noisy data or data that contains a large number of duplicates. The later scenario is common with localisation data where multiple frames may contain the same fluorophore.
The Clustering distance parameter can be chosen by using a k-nearest neighbour (KNN) distance graph, plotting the distance to the k = MinPoints - 1 nearest neighbour in descending order (Figure 6.15). If too small then a large amount of the data will not be clustered. Too large and the clusters will start to merge. A Noise parameter can be used to indicate a distance threshold by excluding a fraction of the KNN graph, ordered from the largest KNN distance.
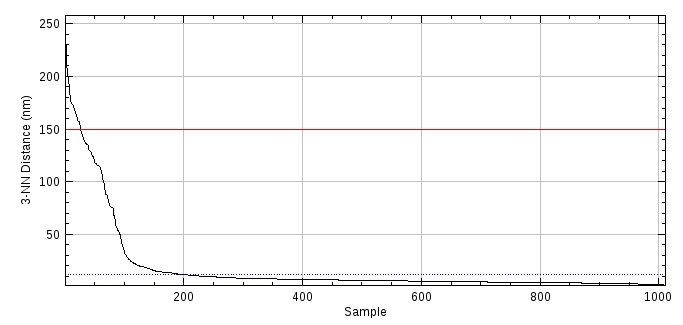
Fig. 6.15 DBSCAN K-nearest neighbour distance graph.¶
The distance to the kth nearest neighbour for a random sample of points is plotted in descending order. An estimate for the DBSCAN clustering radius can be taken from the “elbow” of the plot. The red line shows the current Clustering distance; the blue line is the distance defined by excluding the lowest fraction as specified by the Noise parameter.
6.13.2. Parameters¶
The following options are available:
Parameter |
Description |
|---|---|
Input |
Select the input results to analyse. |
Ignore Z |
Set to true to ignore the z coordinate in 3D data and perform 2D clustering. The default is 3D clustering for 3D datasets. Note: The visualisation of clustering results is optimised for 2D. For 3D data the results will be viewed using a projection onto the XY plane. |
Min points |
The minimum number of neighbours required to create a cluster. |
Noise |
The fraction of data (ordered from the largest KNN distance) to exclude when plotting the estimated clustering distance on the KNN graph. |
Samples |
The number of random points to choose from the data to construct the KNN graph. If set to below 1 then all data points will be processed. |
Sample Fraction |
The fraction of the data to sample to construct the KNN graph. If set to 0 then all data points will be processed. Note: If either |
Clustering distance |
The distance used to define the local neighbourhood of a point. |
Core points |
Only include core points in clusters. These are points with This option ensures the output clusters are independent of the processing order; otherwise non-core points may be allocated to different clusters depending on processing order. |
Show table |
Show the clusters in a results table. The sort order for the table data can be configured. |
Image scale |
Specify the scale for the output image. The size of the image is the raw pixel bounds for the localisation data multiplied by the scale. |
Image mode |
Specify the mode used to colour the image localisations.
The |
Outline |
Specify how clusters should be outlined on the image. The outline algorithm can be configured using the Outlines can be optionally saved to the The concave hull can use the K-nearest neighbour method of Moreira and Santos (2007), or the digging algorithm of Park and Oh (2012). For the digging algorithm the threshold is the allowed ratio between the edge distance and the distance to the internal point; a higher threshold results in a less concave hull. |
Preview |
Enables the live preview of results. Settings changes will result in live update of the displayed results. The
|
Debug |
Extra option: If true write debugging information to the Java console. |
6.13.3. Analysis¶
The DBSCAN plugin records processing details to the ImageJ log window. This includes:
The settings for DBSCAN.
The processing time for the algorithm which may include sampling the KNN data and computing the neighbourhoods. This can be used to performance tune the parameters if the processing is taking too long.
The number of clusters.
If the live preview is active the plugin also records the Rand index comparing the current clustering with the previous clustering. This provides an indication of how much the clustering has changed with settings changes.
6.13.4. Results¶
The DBSCAN plugin will create results displayed in windows. If the OK button is pressed the final settings will be used to update any live preview results. If live preview was not enabled then the results will be displayed. Note that the selection events are only created and handled when the DBSCAN plugin dialog is open. After the dialog has been closed the results windows are no longer interactive.
DBSCAN will save the clustering results to a dataset in memory. Localisations will have an ID assigned if they were part of a cluster.
An example of the clusters overlaid on an image is shown in Figure 6.16. Notes:
The image can be zoomed using the
+and-keys.Holding the
Spacebar allows the canvas to be scrolled using mouse drag.

Fig. 6.16 DBSCAN clusters outline.¶
The outline, representing the convex hull of clusters, is coloured using a look-up table to maximise separation of colours and overlaid on a super-resolution image of the localisations.
6.14. Draw Clusters¶
Draws collections of localisations with the same ID on an image, for example the output from Trace Molecules, Cluster Molecules or Trace Diffusion.
The Draw Clusters plugin collects localisations together with the same ID into clusters. If
localisations have no ID they are ignored. The localisations in each cluster are then sorted by start frame to create an ordered trace. Each cluster is then drawn on a selected image, or a new empty image using an ImageJ overlay. The size of the empty image can be specified but the plugin will zoom a small image until the display window is 500 pixels on the long edge. The overlay can be removed using Image > Overlay > Remove Overlay.
The user has the option to draw the cluster as a series of points (a cluster) or as a connected line (a trace). Plotting points is appropriate when the clusters contain multiple localisations that do not represent a single molecule. Plotting a line is appropriate when the cluster represents a single molecule’s position through time.
If an input image is selected then the number of time frames in the image is compared with the maximum start frame in all the localisations. If the image stack is large enough the plugin can draw each cluster on the specific frame containing the localisation. In this case the entire cluster is drawn and the point contained in that particular frame is highlighted using a cross (see Figure 6.17).

Fig. 6.17 Draw Clusters example¶
The line shows the entire trace of the cluster. The cross is used to mark the point contained in the current frame.
The following options are available:
Parameter |
Description |
|---|---|
Input |
Select the input results to draw. The list only contains results where all the localisations have an ID. |
Image |
Specify the output image to draw on. If |
Image size |
The size of the default output image on the long edge. Small images will be zoomed. |
Expand to singles |
Expand any localisation with a different start and end frame into a series of singles (with the same coordinates). This option is useful for drawing multi-frame localisations, for example centroid representations of clusters. The expansion is performed before the size filtering step. |
Min size |
The minimum size of clusters. All clusters below this will be ignored. |
Max size |
The maximum size of clusters. All clusters above this will be ignored. Set below the |
Traces |
Select this option to assume the localisations are connected as a time-series trace. The output will draw lines connecting the points. If not selected the output will draw each point individually. If clusters have more than one localisation per frame then this mode is disabled. |
Spline fit |
If selected the line will be drawn as a spline fit. This is only valid when |
Use stack position |
If selected the plugin will draw each cluster on the specific frame containing the localisation. If an output image is selected then the stack must contain enough frames to plot all the localisations. If no output image is selected then the default output image will be created as a stack of the required size. |
Colour |
Specify how the cluster colour is assigned from the look-up table. The LUT is applied as a linear mapping from zero to the maximum value in the selected data. If clusters are filtered then the maximum value remaining may change and the same cluster may change colour. Note: The |
LUT |
Specify the look-up table (i.e. the colour) used to plot the clusters. Each cluster is a single colour. The colour is varied according to the order the clusters are processed. Note: Single colour LUTs vary the intensity of the colour from 50% to 100% to provide identification of the order. |
Invert LUT |
Set to true to invert the LUT. |
Line width |
Specify the line width. Use zero to draw lines with a 1 pixel stroke width regardless of the magnification. |
6.14.1. Drawing Cluster Centroids¶
Note that the Draw Clusters plugin will draw all the members of a cluster on the image. If you wish to draw only the centroids then you should either:
Load the centroids from a pre-processed file as a single localisation with a unique ID
Run a clustering algorithm (
Trace MoleculesorCluster Molecules) and then select an appropriate centroids dataset that is stored in memory
If you wish to draw the cluster centroid on each frame that contains a member of the cluster then you can use the Expand to singles and Use stack position options.
6.15. Density Image¶
Analyses the local density around each localisation and outputs an image using the density score. Can optionally filter localisations based on the density score into a new results set.
The Density Image plugin counts the number of localisations in the neighbourhood of each localisation. The score is then used to create an image of the density of localisations. The following options are available:
Parameter |
Description |
|---|---|
Input |
Select the input results to analyse. |
Radius |
Specify the radius of the local region around each localisation. |
Distance unit |
Specify the distance unit of the radius. |
Use ROI |
If selected the user will be presented with a dialog allowing the selection of an image with an area ROI drawn on. If only one image has an area ROI it will be chosen automatically. The ROI will be scaled to the dimensions of the input results and only localisations within this region analysed. This option allows the user to construct density images using only part of the input image results. |
Adjust for border |
Localisations that are close to the edge of the analysis region will have a local area that extends outside the region. This will result in under-counting of neighbours. This can be compensated for by scaling the count of neighbours using the proportion of area sampled, e.g. if 40% of the area is sampled (60% missing) the count is multiplied by 100/40. |
Image Scale |
Specify the scale of the output image relative to the input results. |
Cumulative image |
The output image may contain several localisations on the same pixel. If |
Use square approximation |
If enabled use a square neighbour region with edges of 2 x radius. If disabled use a circular neighbour region with the specified radius. Using the square approximation avoids computation of pairwise distances by assigning localisations to a grid and summing the counts within the grid neighbourhood. It is very fast when using extremely large datasets. |
Square resolution |
Define how many grid points will be used per pixel for |
Score |
Define the score that will be output in the density image. See section 6.15.1: Available Density Score functions. |
Filter localisations |
Remove all localisations that have a score below the specified value. The remaining localisations will be stored in a new results set in memory. The results will be named using the source results name plus the suffix |
Filter threshold |
Define the filter threshold. Most score functions will be either zero or 1 if the density matches that expected for randomly distributed particles. |
Compute Ripley’s L plot |
Analyse the data using a range of distance thresholds and compute the Ripley’s L-score for each. Show a plot of the L-score against the distance threshold. See section 6.15.2: Ripley’s L-plot. |
6.15.1. Available Density Score functions¶
The plugin computes the number of localisations in a region surrounding each localisation. This value is biased by the total number of localisations and the total area sampled. The number can be normalised using the sample size and sample area to produce different scores. The scores are based on the Ripley’s K and L functions. Ripley’s K-function describes the fraction of points within a distance threshold r normalised by the average density of points:
where I is the indicator function, \(d_{\mathit{ij}}\) is the Euclidean distance between the ith and jth points in a data set of n points, and \(\lambda\) is the average density of points, generally estimated as \(\frac{n}{A}\), where A is the area of the region containing all points. Note that the indicator function has a value of 1 for all elements (\(d_{\mathit{ij}}\)) that are a member of a set (in this case \(d_{\mathit{ij}} < r\)), otherwise it is zero. If the points are randomly distributed then K(r) should be equal to \(\pi r^2\).
The K function can be variance normalised to the L function:
The L function should be equal to r if the points are randomly distributed and its variance should be approximately constant in r. A plot of \(L(r)-r\) should follow the horizontal zero-axis if the data are dispersed using a homogeneous Poisson process. A plot of \((L(r)-r)/r\) will also be zero but should have equal variance at any r thus the magnitude of deviations from zero can be directly compared for any r.
Note that the K and L functions apply to an entire dataset. However it is possible to produce a per localisation K or L score as follows.
Since the count of localisations is expected to be the area of the local region multiplied by the average sample density (\(\lambda\)) then the \(K_{i}(r)\) score is expected to be the area of the local region.
The \(K_{i}(r)\) score can be normalised by the local region area and should be equal to 1. As before the \(K_{i}(r)\) score can be variance normalised to an L score:
In this case the L-score is normalised by \(\pi\). If using a square approximation then the normalisation factor for the area of a square is 4.
The \(L_{i}(r)\) score should be equal to r if the points are randomly distributed. The following scores are supported in the plugin:
Score |
Description |
|---|---|
Density |
The count of the number of localisations in the region around a localisation. |
\(K_{i}(r)\) |
K score. Should be equal to the local region area. |
\(K_{i}(r)/\mathit{Area}\) |
Should be equal to 1. |
\(L_{i}(r)\) |
Should be equal to the radius. |
\(L_{i}(r)-r\) |
Should be equal to zero. |
\(L_{i}(r)/r\) |
Should be equal to one. Scores should be comparable across different radii. |
\((L_{i}(r)-r)/r\) |
Should be equal to zero. Scores should be comparable across different radii. |
6.15.2. Ripley’s L-plot¶
If the Compute L plot option is selected then the plugin will compute the L-score for a range of radii. A dialog is presented allowing the user to select the L-plot score function, Min radius, Max Radius and the Increment used to move between them. A plot is produced showing the score for each radius. The \((L_{i}(r)-r)\) score should be equal to zero for homogeneous data. If further normalised by \(r\) the score is comparable across radii.
If the Confidence intervals parameter is enabled the plugin will create 99 random simulations of the given sample size in the same sample area. The score is computed for each simulation and the upper (blue) and lower (red) bounds of the confidence intervals are shown on the chart. If the actual data values lies outside the confidence intervals then it is a non-random distribution with 99% confidence. Note that the simulations are computed using multiple threads; the number of threads is set in Edit > options > Memory & Threads....
The L-plot use square approximation option allows use of a look-up table of neighbour counts. This computes each score in \(O(n)\) time, where \(n\) is the number of localisations, and is suitable for large datasets and/or radii. The option has a large memory overhead. Reducing the number of threads can allow the plugin to run without raising an out-of-memory error.
An example of Ripley’s L-plot is shown in Table 6.1. The figure shows the L-plot for simulated localisations of fluorophores. The raw data show significant deviation from a random distribution (A). Tracing of the localisations with a suitable time and distance threshold collates the individual localisations into single molecule traces. These do not show any deviation from a random distribution (B).
|
|
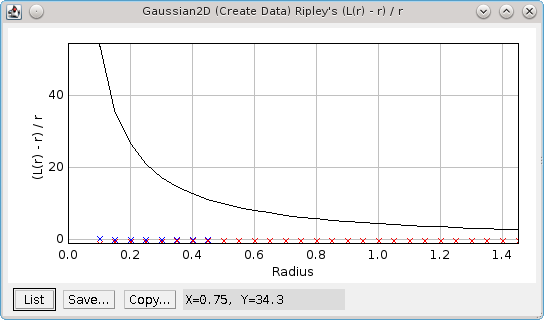
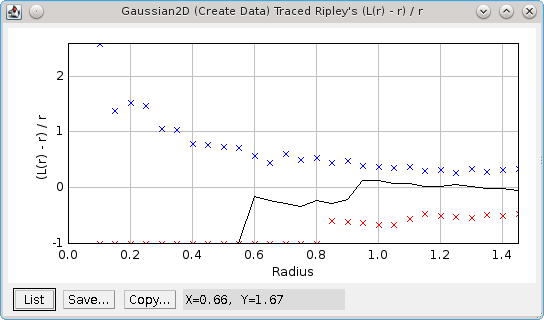
6.16. Dark Time Analysis¶
The Dark Time Analysis plugin computes a dark time histogram for blinking fluorophores and then outputs the time threshold required to capture a specified percentage of the blinks.
Fluorophores can be inactive (dark) for a variable amount of time between fluorescent bursts. If tracing is to be used to connect all separate bursts from the same fluorophore into a single molecule then the tracing must be done using the maximum dark time expected from the fluorophore. This can be estimated using the Dark Time Analysis plugin, ideally on an image sample of fluorophores captured under the same imaging conditions as will be used for in vivo experiments. The most success will be obtained using fixed fluorophore samples.
The plugin performs tracing or clustering on the localisations using a specified search distance and the maximum number of frames in the results for the time threshold. This allows the algorithm to connect a localisation in the first frame to the last frame. The maximum dark time can optionally be limited. All the algorithms only allow localisations to be joined to the closest localisation in a different frame (i.e. not the same frame). However only those closer than the distance threshold are joined.
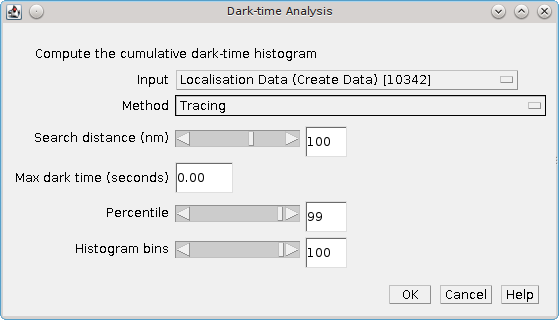
Fig. 6.18 Dark-time Analysis dialog¶
Figure 6.18 shows the plugin dialag. The plugin supports the following parameters:
Parameter |
Description |
|---|---|
Input |
Specify the results to use for analysis. |
Method |
Specify the tracing or clustering method. Details of the tracing and clustering algorithms can be found in sections 6.2: Trace Molecules and 6.3: Cluster Molecules. |
Search distance (nm) |
Specify the maximum distance between localisations to be part of the same molecule. |
Max dark time (seconds) |
Specify the maximum allowed dark time between localisations to analyse. Any dark time distances above this are ignored. Set to zero to allow any dark time. |
Percentile |
Specify the percentile limit used to report the maximum dark-time. |
Histogram bins |
Specify the number of bins to use for the histograms. |
When started the progress of the algorithm is shown on the ImageJ task bar. When tracing/clustering is complete the plugin produces a histogram and cumulative histogram of the dark time for all traces. The dark-time corresponding to the specified percentile is then reported to the ImageJ log window.
6.17. Blink Estimator¶
Estimate the blinking rate of fluorophores in a results set.
The
Blink Estimator
uses the method of Annibale et al (2011) to estimate the blinking rate of a fluorophore. The method is based on performing trace analysis of the localisations using different time thresholds. The distance threshold used for the trace analysis is set using a factor of the average precision of all the localisations in the sample. When the time threshold is 1 then the number of traces will be equal to the total number of flourescent bursts in the sample. As the time threshold is increased the number of traces should asymptote at the number of molecules in the sample, assuming that no missed localisation counts occur. The curve of traces against time threshold can be fitted using the following formula:
where \(t_d\) is the dark time of the fluorophore (time-threshold), \(N(t_d)\) is the number of traces at \(t_d\), \(n_{\mathit{blink}}\) is the average number of blinks per fluorophore, \(t_{\mathit{off}}\) is the average off time for fluorophores. To avoid the problems associated with missed counts Annibale et al only fit this formula to the first five data points of the curve.
The Blink Estimator computes the \(N(t_d)\) curve and fits the curve to the specified formula. By default the plugin fits the curve and shows a plot of the \(N(t_d)\) curve with the fitted line (see Figure 6.19). The fit parameters are reported to the ImageJ log window.
Alternatively the plugin can fit the curve multiple times using a different number of points for each fit. In this case the output is a set of plots showing the values of each of the fitted parameters against the number of fitted points.
Note that tracing localisations through time also requires a distance threshold to determine if the two coordinates are the same molecule. The distance threshold used for the analysis is computed using the average precision of the localisations multiplied by a search factor. The average precision is determined by fitting a skewed Gaussian to a histogram of the localisation precision. This fit can optionally be displayed.
The following parameters can be set within the plugin to control the output:
Parameter |
Description |
|---|---|
Input |
Select the input results set. |
Max dark time |
The maximum dark time to use for the \(N(t_d)\) plot. |
Histogram bins |
The number of histogram bins. |
Show histogram |
Show the histogram of the precision along with the fitted skewed Gaussian curve. |
Search distance |
Define the distance threshold for trace analysis. |
Relative distance |
If selected the |
Fitted points |
The number of points to fit on the \(N(t_d)\) curve. Must be 4 or more. |
Range of fitted points |
The maximum number of additional points to fit for variation analysis. Fit are computed in the interval |
Time at lower bound |
When constructing the dark time curve the number of frames used for tracing is converted to time in milliseconds. Set to true to output time as nFrames × msPerFrame. Set to false to output time as (nFrames+1) × msPerFrame. This setting will shift the time axis of the curve and will produce different curve fitting results. Simulations using the |
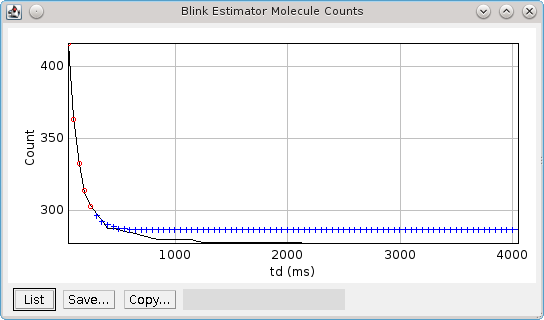
Fig. 6.19 Curve output from the Blink Estimator.¶
The curve data is plotted in black. The red circles show the fitted points. The blue crosses indicate where the fitted line will asymptote.
6.18. Time Correlated (TC-PALM) Analysis¶
Performs time correlated photo-activated light microscopy (TC-PALM) analysis (see Cisse et al, 2013). This plugin accepts a results set from memory. The plugin will use any assigned IDs to group localisations for analysis. All localisations with an ID of zero are assigned an ID. The support for grouped localisations allows the plugin to analyse groups of localisations together: an entire group can be selected even if the region of interest only contains some of the localisations; and groups can be selected and displayed together. It is suggested that the input data is a results set that has been clustered using a distance threshold that collects data within the range of interest.
The analysis uses a cumulative histogram of the number of localisations against time. The profile of the activation against time chart can be used to identify clustering that occurs continuously over the imaging lifetime or during a short interval of the entire imaging lifetime (time correlated activation). If the experiment had constant activation of fluorophores over the lifetime then the chart will show an initial steep gradient that gradually falls off as the fluorophores photo-bleach. If there is selective clustering of fluorophores, for example in response to a stage of the cell life cycle, these bursts of activations will appear as a steep gradient on the activation chart.
Display of the activations against time chart for an entire set of localisations will contain too much information and the bursts may not be visible over the noise of constant activation, or the simultaneous bursts in multiple locations in the image. The plugin thus provides a super-resolution image for an overview of the localisation data. A region of interest (ROI) can be marked on the image and the plugin will create the activations verses time plot.
When the plugin is executed the dataset and image rendering options must be specified.
Parameter |
Description |
|---|---|
Input |
Select the input results set. |
Image |
Specify the rendering settings for the super-resolution image. Extra options are available using the The options are the same as those available in the |
When the super-resolution image has been constructed a region of interest (ROI) is used to mark an area on the super-resolution image for analysis. The ROI may be created using any area ROI tool for example rectangle, oval, polygon or freehand. All groups that fit entirely within the region are analysed. Alternatively all groups that have at least one localisation within the region are analysed. To assist in analysing the activations verses time chart the range of localisations can be bracketed using a minimum and maximum frame. This allows zooming in on a part of the imaging lifetime. A dialog is shown to control the TC-PALM analysis.
Parameter |
Description |
|---|---|
ROI intersects |
Set to true to add all groups that have at least one localisation within the region to the current clusters. If false then all localisations from the group must be within the region to be included in the current groups. |
Min frame |
The minimum frame for localisations that are extracted for analysis. |
Max Frame |
The maximum frame for localisations that are extracted for analysis. |
Fixed time axis |
Set to true to use the full time length of the input data on the time axis of the plots. If |
Time in seconds |
Set to true to plot seconds on the activations verses time plot. The default is frames. |
Dark time tolerance |
The maximum dark time allowed between activations for connection into a continuous burst. |
Min cluster size |
The minimum size for a continuous burst of activations. |
6.18.1. Output¶
The TC-PALM Analysis plugin is interactive. The dialog controlling selection of the current clusters is non-blocking to allow interaction with other windows within ImageJ. Updates to the ROI on the super-resolution image or the selection parameters will result in identification of a new set of current groups.
When the ROI or other parameters controlling the selection are updated the current groups will be identified. The square bounds from the ROI are used to construct a loop view of the region. Any data that is outside the ROI but was included using the ROI intersects parameter will not be visible. The settings for the loop view can be adjusted using the Loop settings button. The default loop view has a fixed size and thus smaller ROIs are magnified appropriately to allow an overview of the selected region. This can be changed to use a fixed scale or a fixed output pixel size. The data from the current groups is then displayed in plots and a results table.
The current groups are shown on an activations verses time plot (see Figure 6.20). Each frame where one or more activations occurred is added as an individual line. High counts and occurrences close in time are easily visible on this plot.
Fig. 6.20 TC-PALM activations verses time plot. The number of activations for each frame is shown as a separate line on the plot.¶
The activations are aggregated into a total activations verses time plot (see Figure 6.21). Note that multiple activations may occur at the same time. This is named a clash and the total number of clashes are displayed as a label on the plot. The number of clashes provides an indication of whether time correlated clustering is due to single or multiple fluorophores.
Fig. 6.21 TC-PALM total activations verses time plot. Highlighted activation bursts are identified using continuous regions of increasing activations within an allowed dark time tolerance of 40 frames and minimum cluster size of 20.¶
The total activations plot is analysed to identify bursts of activations that occur within a continuous time period. A dark time tolerance allows periods of no activations within the same burst. The analysis identifies bursts of activations that are connected within the dark time tolerance and above the minimum cluster size. All bursts above the minimum cluster size are shown in a clusters table and highlighted on the total activations plot. The localisations from these bursts are drawn on the super-resolution images using a point ROI overlay. This can be used to determine if localisations that are close in time are also close in space. This is a time correlated clustering event. The Dark time tolerance and Min cluster size parameters can be adjusted and the results updated in real-time. Selecting a cluster in the clusters table will draw the hull of the cluster on the loop image using an ROI.
By default all the localisation groups within the ROI are analysed. These groups are recorded in a table. The table records the average coordinates of the group, the size, the start frame and the duration. The default table sort order uses the start frame of the group. The sort can be changed by clicking on a table header to sort by that column.
The localisation groups table can be used to select a subset of the current data for analysis. Lines can be selected using a single-click. Use the shift key to select multiple lines with a single mouse click starting from a previously selected line. Use the control key to select lines to add or remove from the selection allowing selection of discontinuous ranges. The selected data are sorted by start time and joined into bursts if the end of one group is within a dark time tolerance to the start of the next. Each burst is highlighted on the total activations verses time plot. Note that for convenience the Min cluster size parameter is ignored allowing the manually selected data to always be displayed on the total activations plot. All the localisations from the selected data are overlaid on the super-resolution images. This manually selected data replaces the results from the automated analysis. The automated analysis results can be recreated by adjusting one of the parameters that affects the input data or the analysis.
6.18.2. Batch ROI Analysis¶
The interactive analysis can be used to explore the data by moving an ROI around the super-resolution image. Alternatively all the ROIs in the ROI manager can be analysed together and the results reported for the entire analysis. Each ROI can be added to the ImageJ ROI manager (using Ctrl+T) so it can be revisited. Clicking the ROI in the ROI manager will re-apply the region to the image and the results are updated in real-time. The Dark time tolerance and Min cluster size parameters can be adjusted using multiple regions so that the parameters are suitable for analysis of all the regions.
The Analysis settings button configures the settings for the analysis including the output options. The Analyse ROIs button will perform analysis on each ROI from the ROI manager. Optionally a check can be made to detect any ROIs that overlap. If any ROIs overlap then a warning is shown as this may lead to double counting of clusters in the results. The overlap check only uses the square bounding rectangle for the overlap analysis so for example touching circular ROIs will be detected as overlapping. You can see overlapping ROIs using the ROI manager Show all function to overlay all ROIs on the super-resolution image. The analysis provides the option to continue or cancel if there are overlapping ROIs.
For each ROI the localisation groups are extracted and the total activations against time profile is constructed. This is used to identify clusters using the Dark time tolerance and Min cluster size parameters. The entire set of clusters from all ROIs are recorded in an All Clusters table. Summary histograms of cluster size, duration, area and density can be displayed. The localisations from the activation clusters are saved to memory using the same name as the input results set with the text TC PALM appended.
The All clusters table stores the settings and ROI used to generate each result. Clicking a line in the table will repeat the analysis for the ROI with the saved settings. The ROI and settings will be applied to the super-resolution image and the plugin dialog.
6.19. Neighbour Analysis¶
Saves all localisations paired with their neighbour (if present) to file.
The Neighbour Analysis plugin searches for the neighbour of each localisation within the given time and distance thresholds. In the event of multiple neighbours the localisation with the highest signal is selected. These are then saved to file as a series of clusters. Each cluster has either one or two entries. The first contains the details of the localisation, the optional second entry contains the details of the neighbour. Note that there is no requirement for neighbours to be symmetric.
This plugin was written to allow off-line analysis of the neighbours of localisations, for example investigation of how average distance, signal strength and frequency of neighbours vary when localisations are categorised using their own signal strength.
6.20. Filter Analysis¶
Performs filtering on a set of categorised localisation results and computes match statistics for each filter.
The Filter Analysis plugin is used to benchmark different methods for filtering the results of fitting a 2D Gaussian to an image. When a Gaussian peak is fitted to an image it has many parameters that are changed in order to optimise the fit of the function to the data. For example the centre of the spot, the width of the spot, etc. It can be difficult to know if the parameters have been adjusted too far and the Gaussian function is no longer a fair representation of the image. This plugin requires the user to prepare input data with fitting results identified as correct or incorrect. The plugin will load the results and then filter them with many different settings. The filtered results are compared with the classifications and various comparison metrics are generated allowing the best filter to be identified.
6.20.1. Input Data¶
The plugin requires a folder containing the results of running
Peak Fit
on one or more images. The results will contain the X and Y coordinates, X and Y standard deviations and amplitude of the Gaussian function. The results will also contain the original pixel value of the peak candidate location. This column must be updated to contain a zero for any result that is incorrect and a non-zero value for any result that is correct. The classification of spots can be performed using any method.
One data preparation method is to manually inspect a set of localisation images and extract entire stacks from the image containing suitable spots. These stacks should contain both on and off frames for the fluorophore and examples of good, medium and poor spots that could be identified manually. The example spots were then manually scored by multiple researchers and a jury system used to score if the frame contained a spot or not. The images were fitted using Peak Fit and the results files updated using the jury classification to mark results as correct/incorrect.
When the plugin is run the user must select a directory. The plugin will attempt to read all the files in the directory as localisation results files. The results are cached in memory. If the same directory is selected the user can opt to re-use the results. Click ‘No’ to re-read the results, for example if the files have been modified with new classifications.
6.20.2. Available Filters¶
When the results have been loaded the user is presented with a dialog as shown in Figure 6.22. There are several filters available with parameters to control them. Enable the filter by using the checkbox for the filter name. Each filter typically has a set of parameters that control the filter. The plugin allows the parameters to be enumerated so that the performance of the filter can be tested. The plugin dialog will allow the minimum and maximum value for the filter to be set along with an increment used to move between them. The filter will be run for each combination of parameters that is to be enumerated to produce a filter set.
Fig. 6.22 Filter Analysis plugin dialog¶
The following filters are available:
Filter |
Description |
|---|---|
SNR Filter |
Remove all results with a Signal-to-Noise Ratio (SNR) below a set value. Additionally remove peaks where the width has expanded above a set ratio from the estimated PSF width. The SNR ratio used is from |
Precision Filter |
Remove all results with a precision below a set value. The precision used is from |
Trace Filter |
Remove all results that do not form part of a molecule trace using the specified time and distance threshold. See section 6.2: Trace Molecules for details of the tracing algorithm. The minimum and maximum time and distance threshold can be configured along with the increments used to move between the min and max. |
Hysteresis SNR filter |
Mark all results with a Signal-to-Noise Ratio (SNR) above an upper level as valid. Remove all results with a Signal-to-Noise Ratio (SNR) below a lower level. Any result with a SNR between the upper and lower levels is a candidate result. Candidates are retained if they can be traced directly or via other candidates to a valid result. Uses the same SNR and width parameters from the |
Hysteresis Precision filter |
Mark all results with a precision below a lower level as valid. Remove all results with a precision above an upper level. Any result with a precision between the upper and lower levels is a candidate result. Candidates are retained if they can be traced traced directly or via other candidates to a valid result. Uses the same precision parameters from the |
Note that the hysteresis filters perform tracing using a time threshold of 1 and a distance threshold of 2x the average precision of the results.
More flexibility over the filters to use in the analysis is provided by using the
Create Filters
and
Filter Analysis (File)
plugins (see sections 6.21 and 6.22).
6.20.3. Additional Parameters¶
After the filters have been configured there are additional parameters controlling the analysis:
Parameter |
Description |
|---|---|
Save filters |
Save the filters to file. The filters can be read using the |
Show table |
Show a table of the analysis results. |
Plot top n |
Produce a plot of the top N filter sets showing their Jaccard score verses a named parameter value. If a filter set contains filters with different named parameters then the filters are plotted in sequential order. |
Calculate sensitivity |
Calculate how sensitive the scoring metric is to a change in each filter parameter. Each filter parameter is adjusted by the delta and the gradient computed at the point of the optimum filter score. |
Delta |
The delta value used to adjust parameters to calculate the sensitivity. |
6.20.4. Output¶
At least one output method must be chosen otherwise the plugin will show an error message.
6.20.4.1. Results Table¶
If Show table is selected the plugin produces a table of the match statistics for the filtered results compared to the categorised inputs. The results for all the filters in a filter set are shown together. An empty row is used to separate filter sets.
The available scores are Precision, Recall, F-score and Jaccard. Details of the match statistics are given in section 13: Comparison Metrics.
6.20.4.2. Plot Output¶
If a value for Plot top n is provided the plugin produces a chart of the Jaccard score against one independent filter variable for each of the top N performing filter sets. An example of the Hysteresis Precision filter chart is shown in Figure 6.23. The chart shows a clear improvement and then fall-off in performance as the lower threshold is increased.
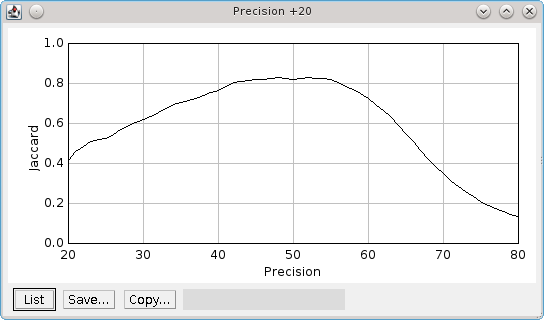
Fig. 6.23 Plot of the Jaccard score verses lower precision limit for the Hysteresis Precision filter.¶
The upper limit for hysteresis thresholding is 20nm higher than the lower limit (+20).
6.20.4.3. Sensitivity Analysis¶
If Calculate sensitivity is selected the plugin produces a table of the sensitivity of each parameter for each unique filter (identified by name). The sensitivity is calculated for the filter parameters that produce the highest Jaccard score. The sensitivity is the partial gradient of the score with respect to each parameter.
If the sensitivity is low then the filter will perform well using a range of parameter values. If the sensitivity is high then the filter performance will rapidly fall-off as the optimum parameter value is changed. Ideally a good filter will have good performance metrics and low sensitivity across all the parameters. It may be better to choose a fil|ter that does not have the highest Jaccard score but has the lowest sensitivity. This filter should perform better on a range of input data.
The sensitivity is calculated by altering each parameter by a relative amount. The delta parameter controls the update magnitude. Note that integer parameters will be correctly adjusted to the next integer. The score is recomputed using the new parameter value following a positive or negative change. The average rate of change of the score is then computed. The sensitivity is output for the Jaccard, Precision and Recall scores. Two scores are output: (a) the raw average change, titled Sensitivity (delta); or (b) the average change divided by the change in the parameter value, titled Sensitivity (unit).
6.21. Create Filters¶
The Create Filters plugin can be used to prepare a large set of filters for use in the Filter Analysis (File) plugin (see section 6.22). The purpose is to create a set of filters that can be applied to a testing dataset to identify the best filter.
The plugin dialog shows a text area where a filter template can be specified as shown in Figure 6.24. If the Show demo filters checkbox is selected then several example filters will be recorded in the ImageJ log.
Fig. 6.24 Create Filters plugin dialog¶
The filter template must be valid XML elements. Each element should take the format of valid XML filters that can be passed to the
Free Filter Results
plugin. An example set of all the valid filters can be output to the ImageJ log window using the
Free Filter Results plugin (see section 5.22).
Each XML filter template is processed into a filter set. The attributes of the filter are scanned for the pattern min:max:increment. If this is found a filter is created with the attribute set at each value from the minimum to the maximum using the specified increment. If not then the filter value is left untouched.
If a filter has multiple attributes then all combinations will be enumerated. Use the Enumerate early attributes first checkbox to enumerate the attributes in the order they appear in the template. Otherwise they will be enumerated in reverse order.
The output filter set will be named using the name of the filter. For example:
<SnrFilter snr="10:20:2"/>
Becomes:
<FilterSet name="SNR">
<filters class="linked-list">
<SnrFilter snr="10"/>
<SnrFilter snr="12"/>
<SnrFilter snr="14"/>
<SnrFilter snr="16"/>
<SnrFilter snr="18"/>
<SnrFilter snr="20"/>
</filters>
</FilterSet>
When the plugin has generated all the filters it will present a file selection dialog allowing the user to specify the output filter file. If the file already exists it will be overwritten.
6.22. Filter Analysis (File)¶
Performs filtering on a set of categorised localisation results and computes match statistics for each filter.
The
Filter Analysis (File)
plugin is similar to the
Filter Analysis
plugin (see section 6.20). The difference is that the plugin will not present options to create filters in the main dialog. Instead the filters are created from an input file that is selected following the main dialog. All other functionality is identical.
The filter file can specify thousands of different filters which are described using XML. This allows combinations of filters to be specified using And and Or filters; this is something that is not possible with the
Filter Analysis
plugin. A filter file can be generated from a filter template by enumerating the filter parameters using the
Create Filters
plugin (see section 6.21).
6.23. Spot Analysis¶
The Spot Analysis plugin is designed to allow analysis of fluorophore blinking kinetics using calibration images.
The plugin allows the user to extract an ROI outlining a fluorophore position from an image and manually mark the frames where a spot is visible. A trace of the image intensity helps the user choose the brightest frames where a spot may be present. The plugin records the signal, on-time and off-time for the fluorophore to files for later analysis.
The plugin has been used to generate distributions for the signal-per-frame, on-times and off-times for mEOS3 fluorophores captured at a frame rate of 50 frames a second (20ms exposure time). At this rate the fluorophore emissions are very faint but frames can be manually labelled as on (or off). By analysing hundreds of spots it is possible to extract distribution parameters that allow the fluorophores to be modelled using the Create Data plugin.
6.23.1. Input Images¶
The purpose of the plugin is to mark the fluorescent bursts from a single fluorophore. Consequently the input images should ideally be of single fluorophores spread evenly on the image and fixed in position. Overlapping fluorophores can be excluded from analysis by only selecting spots that appear distinct. An example input image with a simulated PSF image generated using the Peak Fit plugin is shown in Figure 6.25. A single spot has been selected with an ROI on the PSF image. The selection has been applied to the original image to select the region for analysis.
Fig. 6.25 Example Spot Analysis input image of mEOS3 expressed in S. pombe, fixed and activated at a low power to produce non-overlapping fluorophore bursts.¶
The super-resolution image is a simulated PSF image of localisations with a SNR above 20. A single fluorophore is selected for analysis.
6.23.2. Plugin Interface¶
The Spot Analysis plugin displays a window as shown in Figure 6.26. The window contains a drop down selection list allowing the input image to be selected and various parameters for the analysis can be set. The centre of the window shows the analysis of the current frame from the spot regions. The window then has several buttons allowing different actions. The final region of the window is a list of the currently selected on-frames with the calculated signal (in photons).
Fig. 6.26 Spot Analysis plugin window¶
The following parameters can be set:
Parameters |
Description |
|---|---|
PSF width |
The estimated peak width of the spots (in pixels). This is used to fit the spot region using |
Blur |
The Gaussian blur to apply to create the blurred spot image. The width is relative to the PSF width. |
Gain |
The total gain of the system (ADUs/photon). This is used to convert the counts to photons. |
ms/Frame |
The exposure time. Used to calculate the on/off times in milliseconds. |
Smoothing |
The LOESS smoothing parameter used to create the smoothed average for the profile plots. |
6.23.2.1. Profiling a Spot Region¶
The first action is to select a spot on the input image using a rectangular ROI. It is difficult to see spots on the input image which has many frames and very few fluorescent bursts. Consequently it is recommended that an overview image is created to allow the spots to be identified. This could be a maximum or average intensity projection of the input image. However it is best to identify spots using the Find Peaks plugin and then reconstruct an image using the fitted PSFs. If the image scale is set to 1 then the reconstructed image is the same size as the input image. This allows spots to be outlined on the PSF image and then the ROI reapplied to the original image. An example of this is show in Figure 6.25.
When a suitable spot has been outlined the region can be analysed using the Profile button. The analysis extracts the region into a new image named Spot Analysis Raw spot. This is magnified to allow easier viewing. The same region is subjected to a Gaussian blur and extracted to a new image name Spot Analysis Blur spot. The blurred image can make it easier to see peaks in very noisy images. In addition an average intensity projection is created for the spot region and named Spot Analysis Average spot. The average image can indicate if the spot is fixed and central, moves around the image or overlaps with other signal. An example of the raw, blur and average images are shown in Figure 6.27. The average spot image shows a blurred spot biased to the upper-right corner but the signal is distinct so the spot is suitable for analysis. The Find Peaks fitting algorithm is applied to the current frame of the raw and blurred spot (using the configured PSF width). If a spot is detected within 50% of the distance to the centre of the frame it is marked on the image using an cross overlay.
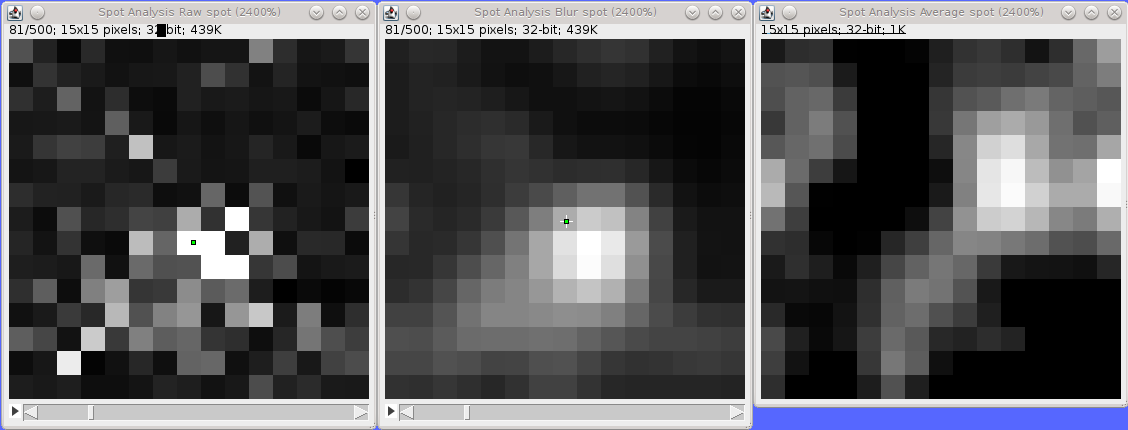
Fig. 6.27 Spot Analysis raw spot, blurred spot and average spot images.¶
The centre of the fitted peak for the raw and blurred image for the current frame is shown using a cross overlay.
The plugin then analyses the spot region and creates profile plots of the mean and the signal standard deviation per frame as shown in Figure 6.28. The currently selected frame in the spot images is shown using a vertical magenta line. The profile can be very noisy and so a LOESS smoothing is applied to the raw plot data to produce a background level (shown in red). Any selected on frames are labelled using magenta circles. In addition the plugin searches the Find Peaks results that are held in memory for any results that were created from the input image. If so then these are potential candidates for on-frames and are shown as cyan squares.
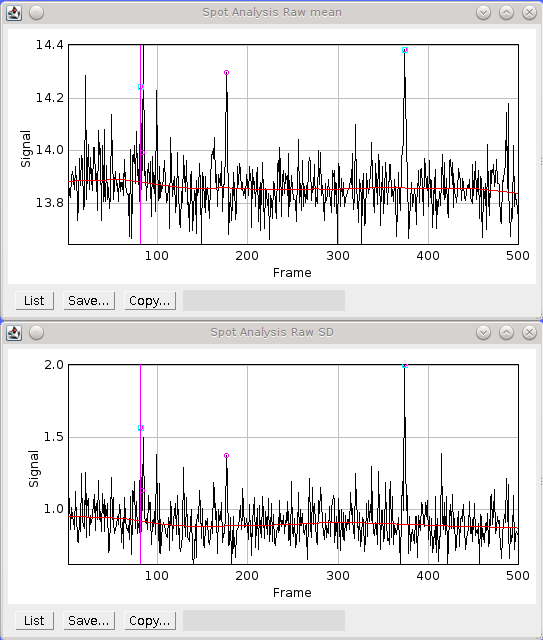
Fig. 6.28 Spot Analysis mean and standard deviation profiles of the spot region.¶
The current frame is shown as a vertical pink line. Candidate on-frames from Peak Fit results are shown as cyan box. Selected on-frames are shown as magenta circles. The red line is the LOESS smoothing of the plot data.
6.23.2.2. Adding On-Frames¶
Any fluorophore on-frame should have a higher mean that the frames around it. These can be easily viewed as spikes on the plot profile and the relevant frames in the spot image inspected.
When the spot image is moved to a new frame the plugin will update the signal and SNR figures for the frame. The signal is calculated as the sum of the raw spot minus the LOESS smoothing fit of the mean profile, i.e. the background. The noise is calculated using the LOESS smoothing fit of the standard deviation profile.
The plugin also runs the Peak Fit algorithm on the raw and blurred spot image. Identified localisations will be marked on the image with an overlay. The signal and SNR for the raw fit and blur fit are shown in the plugin window.
Combining inspection of the spot images with consideration of the signal and SNR of the raw data and fitted data should allow the user to decide if a fluorophore is on in the selected frame. The frame can be added to the on-frames list using the Add button. This can also be performed using a shortcut key mapped to the Spot Analysis (Add) plugin (see section 6.24). By default running the Spot Analysis plugin will bind the Spot Analysis (add) plugin to the number 6 key.
The frame is added to the list in the Spot Analysis window along with the current estimate of the signal for that frame. Note that LOESS smoothing only uses frames that have not been selected as on-frames. Consequently the background and the noise are updated as more on-frames are added to the list.
6.23.2.3. Saving a Fluorophore Sequence¶
When all the on-frames have been marked the fluorophore sequence must be saved using the Save button. This will record the sequence to a summary window as shown in Figure 6.29. The window shows the fluorophore signal, on and off times and number of blinks.
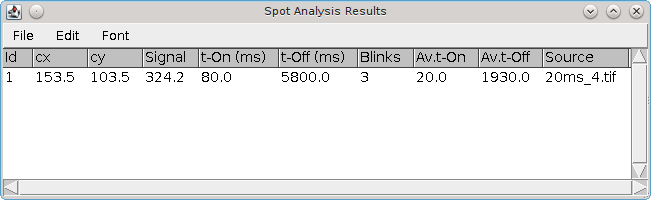
Fig. 6.29 Spot Analysis summary window¶
The Save button can only be pressed once to prevent duplicates in the window. If the sequence list is updated by adding or removing on-frames then the listed can be re-saved. Note that the old sequence will remain in the summary window and the new sequence will have a new ID. The old sequence should be removed using the summary tables Edit > Clear command to remove selected lines.
6.23.3. Spot Analysis Workflow¶
The following workflow is recommended when using the
Spot Analysis
plugin.
Open the next input image. Magnify the image if necessary (
Image > Zoom > In [+]).Run the
Peak Fitplugin to identify peaks with a high SNR (or other criteria to show clear spots). Create a PSF image output with a scale of 1.Select a spot on the PSF image using a new rectangle ROI (or moving the previous one). It is recommended to maintain the same ROI size throughout the analysis. Choose a spot that does not overlap any other spots.
Select the input image and press
Ctrl+Shift+Eto restore selection (apply the same ROI) to the input image. This will outline the spot location on the input image.Press the
Profilebutton. This will produce a profile of the image intensity and standard deviation per frame for the spot. Any localisation results from thePeak Fitplugin are marked on the profile. TheProfilecommand will also extract the ROI to a new detail image and zoom in for easier viewing. A blurred version of the image will also be shown using a Gaussian blur to make the spots more uniform. Contrast may have to be adjusted in these images. The images will be set to the first frame containing a localisation fitting result (or frame 1 if none are available).Scroll left and right through the image using the left/right keys to locate spots. (The original and blurred images will be synchronised.).
Click the
Addbutton when a spot is visible in the frame. Alternatively use the keyboard shortcut that has been mapped to theSpot Analysis (Add)command. The frame will be added to the list with the signal estimate for the spot.Remove bad frames from the list by highlighting them and using the
Removebutton. Double-clicking a frame in the list will select that frame on the detail images.Save the frames listed in the window to the results summary by clicking the
Savebutton. The summary shows the fluorophore signal, on and off times and number of blinks. The list can only be saved once. It must be updated (usingAddorRemove) before it can be saved again.Repeat steps 3-9 for different candidate spots.
Save all the results to file using the
Save Tracesbutton. Only results that are present in the table are saved. Duplicate or unwanted results can be removed using the tableEdit > Clearcommand to remove selected rows.
6.23.4. Results Files¶
Fluorophore sequences in the summary table can be saved to file. The plugin saves only the sequences within the table. Any sequence that is removed from the table using the Edit > Clear command will be discarded. Click the Save Traces button to open a folder selection dialog. Following selection the plugin will write several files to the directory. Any old files will be over-written. The following files are saved:
File |
Description |
|---|---|
traces.txt |
Contains a summary of each fluorophore. Each record shows the ID, centre X and centre Y of the ROI outlining the spot, the total signal, the number of blinks and then a chain of paired start and stop frames for each pulse. This file contains all the information of the other files except the signal-per-frame (see |
tOn.txt |
Contains the on-times for all the results. |
tOff.txt |
Contains the off-times for all the results. |
signal.txt |
Contains the signal for each frame. The frame and signal are shown separated by a space. A header line is added before the signal for each fluorophore showing the ID, number of blinks and the total signal. |
blinks.txt |
Contains the number of blinks for all the results. Blinks are the number of dark times recorded for a fluorophore. It is one less than the number of pulses (on-time events). |
6.24. Spot Analysis (Add)¶
This plugin provides a named plugin command for the Add button of the Spot Analysis plugin.
Any named plugin command can be mapped to a hot key using ImageJ’s Plugins > Shortcuts > Create Shortcut... command. Thus the Add button can be mapped by ImageJ to a keyboard shortcut. This allows the user to scroll through an image generated by the Spot Analysis plugin using the standard left and right arrow keys to move between frames. When a spot is present the user adds the spot to the list by clicking the Add button on the Spot Analysis window. If the Add command is mapped to a shortcut the user can perform the same action using the hotkey. This allows faster analysis of images using only simple keyboard commands.
Running the Spot Analysis plugin will bind the Spot Analysis (Add) plugin to the number 6 key. This can be updated using the commands in the Plugins > Shortcuts menu.
6.25. Crosstalk Activation Analysis¶
Perform crosstalk activation analysis of photo-switchable probes under pulsed light activation. This plugin is based on the methods described in Bates et al (2007) and Bates et al (2012).
Activation analysis is based on the activation of a fluorophore from the flourescence transmission of a closely coupled second chromophore via fluorescence resonance energy transfer (more commonly referred to by the acronym FRET). The second chromophore will be activated by a pulse of light and localisations from the primary fluorophore are only of interest if they begin immediately following a pulse activation.
Using a second chromophore to transfer activation energy to the primary fluorophore allows configuration of an experiment where the wavelength of the pulse activation light can be further separated from the typical activation wavelength of the primary fluorophore. Pairs of fluorophores can be combined with suitable excitation and emission spectra to allow multi-colour imaging to be performed by pulsing with different activation wavelengths and assigning localisations that occur immediately following an activation pulse to the appropriate channel. Note that activation of the primary fluorophore can occur spontaneously or from light pulsed in other wavelengths. This is crosstalk. The crosstalk of a fluorophore pair under the multi-channel experimental conditions (i.e. pulsing with different activation wavelengths in different frames) can be obtained using crosstalk activation analysis. This plugin performs the following analysis on a set of traced localisations:
Identify localisations that appear in the frame after an activator pulse.
For those localisations identify those that are activated more than once after a pulse of any activator wavelength, or the same activator wavelength.
Calculate the ratio of how many times the molecule turns on after an incorrect pulse (channel N) to how many times it turns on after a correct pulse (channel M); this is the crosstalk ratio between channels M and N:
The crosstalk between two channels is the ratio of incorrectly to correctly coloured localisations. A value less than 1 is expected otherwise the fluorophore is not being specifically activated by channel M. Ideally crosstalk should be close to zero. Note that a high crosstalk shows that the experiment conditions will have a lot of localisations mislabelled in the channel representing the ‘wrong’ wavelength due to another channel fluorophore being non-specifically activated. Some level of crosstalk is expected and the ratios can be used to perform spectral unmixing of the identified localisations in a multi-channel imaging experiment. This can be performed using the Pulse Activation Analysis plugin (see 6.26).
The Crosstalk Activation Analysis plugin requires localisations identified from imaging of a single FRET fluorophore-chromophore pair under the conditions of the multi-channel imaging protocol. Thus if 3 channel imaging is desired using 3 FRET pairs of fluorophore-chromophore then 3 rounds of crosstalk analysis must be performed to compute the crosstalk ratio for each pair.
The input localisations must be traced. This allows crosstalk analysis to be separated from how localisations are traced into bursts of fluorescence from the same molecule. Tracing can be done using the Trace Molecules plugin.
6.25.1. Workflow¶
When the plugin is run it displays a dialog where the traced input localisations and number of channels in the full pulse life cycle can be configured.
Parameter |
Description |
|---|---|
Input |
The dataset to analyse. |
Channels |
The number of channels in the full pulse life cycle. This must be at least 2 (otherwise there is no crosstalk) and the supported maximum is currently 3. |
The localisations are then loaded, the calibration is verified and the traces are extracted from the localisations. A dialog is then displayed where the pulse cycle is specified:
Parameter |
Description |
|---|---|
Repeat interval |
The full length of the pulse cycle in frames. |
Dark frames for new activation |
The number of frames between localisations in the same trace used to split the trace into activations. The minimum is 1. This will split any non-continuous localisations from a trace into separate activations. For results where localisations may be dropped during the fitting process this number can be increased, e.g. 5 will only create new activations if there is a gap of 5 frames in the same trace. |
Activation frame C1 |
The activation frame for channel 1. |
Activation frame C2 |
The activation frame for channel 2. |
Activation frame C3 |
The activation frame for channel 3. This is optional depending on the number of configured channels. |
Note: The activation frame for each channel is the frame immediately following the pulse activation laser for the flourophore assigned to channel N. The channel is arbitrary. It is used to allow the output results to be mapped to the pulse wavelengths and fluorophores. The pulse life cycle and any computed crosstalk for each channel will be stored and shown as the default settings in the Pulse Activation Analysis plugin allowing the two plugins to be used together.
When the pulse life cycle has been configured the plugin will split the traces into activations using the Dark frames for new activation parameter. Activations are non-specific if they occur in a frame not following an activation pulse; otherwise the activations are specific to that pulse channel. The plugin records the background (non-specific) and channel (specific) activations rates to the ImageJ log window. These can be used to verify that the pulse life cycle has been correctly configured. Ideally the channel activation rates should be higher than the background activation rate; the target channel activation rate should be far higher than the other channels. In the following example the analysis has been performed on traced data from a non-pulsed experiment and the background rate is the same as the channel activation rate:
Activation rate : Background = 9331/17996 = 0.5185 per frame
Activation rate : Channel 1 = 376/667 = 0.5637 per frame
Activation rate : Channel 2 = 327/667 = 0.4903 per frame
Activation rate : Channel 3 = 322/666 = 0.4835 per frame
In the following example from a simulated 3 channel pulsed experiment the activation rate for target channel 1 is much higher than the other channels:
Activation rate : Background = 17880/26991 = 0.6624 per frame
Activation rate : Channel 1 = 65385/1000 = 65.39 per frame
Activation rate : Channel 2 = 7192/1000 = 7.192 per frame
Activation rate : Channel 3 = 643/1000 = 0.643 per frame
After computing the activation counts the plugin will ask for the target channel. Analysis is performed on the activations to compute the crosstalk ratio(s) for the channel. The plugin will compute 1 ratio for a 2 channel analysis and 2 ratios for a 3 channel analysis. These are saved to memory.
A histogram is constructed of the activation counts for each channel. The crosstalk ratios between channels are displayed on the plot.
6.25.2. Simulated Crosstalk¶
The Crosstalk Activation Analysis plugin requires a set of traced localisations from a pulsed life cycle experiment with conjugated fluorophores. This data can be simulated allowing the plugin to be tested.
The simulation can be run by holding the Shift key down when running the plugin. This will provide an option to run the simulation or to perform crosstalk analysis as normal. Note that the Shift key must be pressed when the main ImageJ window is the active. When run in simulation mode the plugin will create multiple datasets in memory and the crosstalk analysis is not run.
The simulation requires parameters for 3 sets of molecules which are drawn on a fixed size image region. For brevity only the parameters for a single channel are described:
Parameter |
Description |
|---|---|
Molecules C1 |
The number of molecules in channel 1. |
Distribution C1 |
The distribution to use for molecules in channel 1.
In the case of circles or lines the molecule (x,y) positions are sampled uniformly from the perimeter. |
Precision C1 |
The localisation precision of molecules in channel 1. The positions of each localisation for a molecule will be sampled from a Gaussian using the precision for the standard deviation and either x or y for the mean. This simulates a noisy localisation fitting algorithm. |
Crosstalk C21 |
The crosstalk from channel 2 into 1. This is the frequency, expressed as a ratio, where a molecule that should be activated by channel 2 is activated by a pulse from channel 1. |
Crosstalk C31 |
The crosstalk from channel 3 into 1. |
When the simulation is run it uses the following defaults:
Parameter |
Description |
Default |
|---|---|---|
Cycles |
The number of pulse activation life cycles. |
1000 |
Size |
The size of the image region in pixels. |
256 |
Activation Density |
The activation density in molecules/μm. Pixel pitch is 100nm. |
0.1 |
Non-specific frequency |
The background activation frequency. |
0.01 |
Pulse cycle duration |
The duration of a single pulse cycle. |
30 |
Activation frames |
The activation frames for the pulse cycle. |
1, 11, 21 |
Initially the simulation creates the distribution shapes for the molecules in each channel and then samples the shapes to create the molecules. These are then activated in their target channel using an activation probability based on the image region and activation density, i.e. some of the molecules will randomly active each pulse. The crosstalk is used to determine the activation probability for how often the molecules activate following a pulse in their non-target channel. At each pulse the number of activated molecules is sampled from a binomial distribution with the configured activation probability. All non-pulse frame are sampled using the background activation probability. Note that in this simulation a molecule is active for only 1 frame.
When the simulation is complete the actual crosstalk for each channel is computed and recorded in the ImageJ log window with the configured values and the actual crosstalk after the -> text:
Simulated crosstalk C12 0.05285->0.05185, C13 0.1264->0.1257
Simulated crosstalk C21 0.07117->0.07333, C23 0.09783->0.09856
Simulated crosstalk C31 0.137->0.1362, C32 0.1297->0.1286
The simulation is recorded using datasets in memory with the prefix Activation Analysis Simulation. Each localisation is assigned a unique ID. The effect is that tracing of results is perfect and all separate activations are a new trace. A combined dataset is create along with a dataset for each channel with the suffix CN where N is 1, 2, or 3. The channel datasets can be used as input for the Crosstalk Analysis Plugin as they represent the imaging of 1 fluorophore-chromophore pair under the full imaging pulse life cycle.
For reference a 3 colour image composite is created with dimensions 1024x1024 pixels (see Figure 6.30). This contains the localisations from each channel drawn with perfect spectral unmixing; each set of localisations is drawn on the correct channel regardless of whether it was due to an activation in the correct or incorrect pulse. This is a reference image for a perfect result. There is currently not an option to draw the localisations with colours associated with the pulse activation frame, i.e. the raw spectrally mixed image. This can be done using no crosstalk correction in the Pulse Activation Analysis plugin (see 6.26).
After the simulation has finished the Crosstalk Activation Analysis plugin can be run again on any of the simulation channel datasets. The pulse cycle will be correctly configured for the simulation pulse cycle. The computed crosstalk ratios shown on the results plot should match those logged by the simulation to the ImageJ log window.

Fig. 6.30 Example image of simulated 3 channel data output by the Crosstalk Activation Analysis plugin.¶
6.26. Pulse Activation Analysis¶
Perform multi-channel super-resolution imaging by means of photo-switchable probes and pulsed light activation. This plugin is based on the methods described in Bates et al (2007) and Bates et al (2012). For multi-channel pulse imaging this plugin requires the crosstalk ratios computed using the Crosstalk Activation Analysis plugin (see 6.25).
Pulse imaging is the use of pulsed activation light to activate fluorophores. Localisations that occur immediately after an activation pulse are extracted for analysis. Pulse imaging can use different fluorophores with different activation light to produce multi-channel imaging. This plugin supports up to 3 channels from 3 different activation pulses during a pulse life cycle. When performing multi-channel pulse imaging it is possible that a fluorophore is activated by the incorrect pulse and will be incorrectly labelled in the output results. This is known as crosstalk. The cross talk ratios for a fluorophore can be used to perform spectral unmixing of the raw results. During this process localisations may be reassigned a channel based on the crosstalk ratios and current channel assignments of their local neighbourhood.
This plugin performs the following analysis on a set of traced localisations:
Identify localisations that appear in the frame after an activator pulse (specific activations).
Identify localisations that do not appear in the frame after an activator pulse (non-specific activations).
Perform specific activation correction. This reassigns localisations to a new channel using the assignments of the local neighbourhood.
Perform non-specific activation correction. This reassigns localisations to a new channel using the assignments of the local neighbourhood.
Outputs the assigned localisations to memory.
Outputs the assigned localisations to an image.
The quality of the output of the crosstalk correction procedure is subjective and depends on the current parameters. The plugin provides a live preview mode allowing the settings for correction to be changed and the results viewed dynamically.
6.26.1. Crosstalk Correction¶
For each localisation the count of neighbours assigned to each channel is created. The local neighbourhood is defined by a radius. The observed local densities (od) of each channel are converted to the true local densities (d) for each channel using the crosstalk ratios (c).
For 2-channel imaging the following equations are solved for d:
For 3-channel imaging the following equations are solved for d:
The probability the assignment is correct is computed as:
This is a measure of how much crosstalk effected the observed density in a specific channel. If this is below a threshold then then localisation can be removed as noise. This is computed for specific activations.
The probability of each channel can be computed as:
Note this is different from computing the probability of the channel being correct. This value is a simple probability using the local density in each channel. This is computed for specific activations after unmixing or for non-specific activations using the local density of specific activations.
Correction uses the following methods:
Mode |
Description |
|---|---|
None |
No correction. |
Subtraction |
Remove activations with a probability of correct assignment (\(p_{\mathit{correct}}\)) below a specified threshold. Only available for specific activations. There is no probability of correct assignment for non-specific activations since they are not assigned by pulse activation. |
Most likely |
Assigns the activation to the channel with the highest probability (\(p_i\)). If the probability is below a specified threshold then remove the activation. In the event of a tie between two channels a random channel is selected. |
Weighted random |
Assign the activation randomly using the probabilities as weights. This only uses probabilities above a specified threshold to ignore unlikely results. |
In all cases correction is only applied if there are enough neighbours as specified by a threshold value. Otherwise the activation is removed from output.
6.26.2. Workflow¶
When the plugin is run it displays a dialog where the traced input localisations and number of channels in the full pulse life cycle can be configured.
Parameter |
Description |
|---|---|
Input |
The dataset to analyse. |
Channels |
The number of channels in the full pulse life cycle. This must be at least 1 and the supported maximum is currently 3. When using 1 channel there is no unmixing. This option can be used to view the localisation data for a single channel without any unmixing. This provides a reference for the quality of the unmixing process. |
The localisations are then loaded, the calibration is verified and the traces are extracted from the localisations. A dialog is then displayed where the pulse cycle is specified:
Parameter |
Description |
|---|---|
Repeat interval |
The full length of the pulse cycle in frames. |
Dark frames for new activation |
The number of frames between localisations in the same trace used to split the trace into activations. The minimum is 1. This will split any non-continuous localisations from a trace into separate activations. For results where localisations may be dropped during the fitting process this number can be increased, e.g. 5 will only create new activations if there is a gap of 5 frames in the same trace. |
Activation frame C1 |
The activation frame for channel 1. |
Activation frame C2 |
The activation frame for channel 2. |
Activation frame C3 |
The activation frame for channel 3. This is optional depending on the number of configured channels. |
Note: The activation frame for each channel is the frame immediately following the pulse activation laser for the flourophore assigned to channel N. The channel is arbitrary. It must be mapped to the same pulse life cycle used in the Crosstalk Analysis Plugin. The plugin will remember the settings and these should not have to be adjusted.
When the pulse life cycle has been configured the plugin will split the traces into activations using the Dark frames for new activation parameter. Activations are non-specific if they occur in a frame not following an activation pulse; otherwise the activations are specific to that pulse channel. The plugin records the background (non-specific) and channel (specific) activations rates to the ImageJ log window. These can be used to verify that the pulse life cycle has been correctly configured. Ideally the channel activation rates should be higher than the background activation rate.
After computing the activation counts the plugin will show a dialog to configure the output. If a multi-channel pulse life cycle has been specified there are options to perform crosstalk correction. The plugin provides a live preview mode allowing the settings to be changed and the results viewed dynamically. The following parameters are available:
Parameter |
Description |
|---|---|
Crosstalk MN |
The crosstalk ratios. For 2 channel mode these will be 21 and 12. For 3 channel mode these will be 21, 31, 12, 32, 13 and 23. |
Local density radius |
The neighbourhood radius (in nm). |
Min neighbours |
The minimum number of neighbours to perform crosstalk correction. If the neighbour count is below this level then correction will remove the activation. |
Crosstalk correction |
The crosstalk correction mode (see 6.26.1). |
Crosstalk correction cutoff CN |
The threshold below which activation probabilities are ignored. This threshold applies to probabilities computed for the correction (see 6.26.1). Applies to correction in channel N. |
Nonspecific assignment cutoff |
The threshold below which activation probabilities are ignored. This threshold applies to probabilities computed for the correction (see 6.26.1). Applies to correction of non-specific assignments. |
Image |
The type of output image. The image can be configured (see 4.2.8: Results Parameters). If running in multi-channel mode the plugin will create 2 or 3 images then combine them to a composite image using RGB colours. |
Preview |
If true show live results. |
Draw loop |
A button which creates a loop view of any current area ROI marked on the localisations image. The view will mark activations using an overlay of cross-hairs. It can be zoomed and the cross-hairs will not re-scale allowing detailed inspection of local regions. An example of the loop view before and after correction is shown in Figure 6.31 and Figure 6.32. |
Magnification |
The magnification for the loop view. |
Each computation of new results will be saved to memory with the prefix of the input dataset name and a suffix of Pulse Activation Analysis with an optional channel suffix for 2 or 3 channel analysis.

Fig. 6.31 Example loop view from the Pulse Activation Analysis plugin with no correction.¶
Each cross hair represents an activation. Colours represent the channel: red (1); green (2); and blue (3).

Fig. 6.32 Example loop view from the Pulse Activation Analysis plugin with subtraction correction.¶
Each cross hair represents an activation. Colours represent the channel: red (1); green (2); and blue (3). Subtraction correction was performed by removing all activations with a correct assignment probability of below 50%.
6.27. Density Estimator¶
Estimates the local density using squares of size \(N\) around localisations. The size \(N\) should reflect the extent of the PSF in pixels. All overlapping PSFs are joined to an area and the density of localisations in each area is computed. Non-overlapping PSFs are single isolated localisations which have a minimum density defined as \(N^{-2}\). These can optionally be included in the analysis or excluded (as the density of neighbours around the singles is effectively zero).
Parameter |
Description |
|---|---|
Input |
The results set to analyse. |
Border |
The border around each localisation. The size of the square region is \(N = 2b+1\) with \(b\) the border. |
Include singles |
Include singles in the analysis. |
All localisations from each frame are analysed independently. The results are then displayed as an XY scatter plot of the local density against the frame and the local density is shown as a histogram.
6.28. Fourier Image Resolution¶
Calculate the resolution of an image using Fourier Ring Correlation (FRC).
This plugin is based on the FIRE (Fourier Image REsolution) plugin produced as part of the paper by Niewenhuizen, et al (2013). Changes to the original functionality include:
Additional options for computation of the FRC curves
Improved determination of FRC line crossing points
Speed optimisations
Support for multi-threaded random repeats
Additional functionality for correction of spurious correlations has been added based on Matlab code kindly provided by Prof. Bernd Reiger (corresponding author of the FIRE paper).
Fourier Ring Correlation computes the correlation between the features of two images at a certain spatial frequency. A 2D image is transformed into the frequency domain using a Fourier transform. The frequency image represents the amplitude and phase of the original data at different frequencies. These can be visualised as a 2D image, the centre of the image represents the lowest spatial frequencies moving to the highest frequencies at the edge of the image. Points taken from a ring drawn around the centre will represent all the amplitude and phases present at a single frequency. Two images can be compared at a given frequency by measuring the correlation of the data sampled from the same ring on both images. This is the Fourier Ring Correlation (FRC).
To compute the image resolution of a set of localisations requires the following steps:
Produce two super-resolution images using the localisation data
Transform the two images to the frequency domain
Compute the FRC between the two images at all the available frequencies
Plot the FRC against the frequency. This will gradually fall to zero as the frequency decreases (see Figure 6.33)
Smooth the raw FRC curve using robust local regression (LOESS)
Use the smoothed FRC curve to look-up the spatial frequency corresponding to a correlation threshold (cut-off limit)
The spatial frequency at the correlation limit is the Fourier Image Resolution (FIRE). This can be interpreted as stating that there is no meaningful similarity information at any frequency higher than the resolution, i.e. if the images were reconstructed using only frequencies at this level and above then they would be not be recognised as matching.
6.28.1. Input Data¶
Note that the FRC analysis requires two input images; these are constructed from localisations as super-resolution images. This means that the FRC can be computed using a single input dataset split into two halves to compute the resolution of the data, or using two input datasets to compute the resolution of one dataset against the other. This may be useful if two different super-resolution datasets have been obtained for the same structure for example by using a two-channel experiment with different fluorophores.
In the classic case of a single input dataset the localisations must be split into halves. The plugin provides a framework to do this where all localisations are sorted by time frame. Consecutive localisations are then allocated to a block of set size. The resulting blocks can then be split alternating or randomly between the two output images. Using blocks of localisations sorted by time should reduce the number of occurrences when the same molecule that appears in consecutive frames is split into different images. This artificially increases the resolution as the same molecule is present in both images.
Note that if non-random splitting is performed then the output results will be the same when repeated. If data is split randomly then the output resolution will vary since the super-resolution images are different between repeats. Repeating the analysis multiple times with different splits is used to produce an average resolution and a confidence interval.
When two datasets are used then no splitting is required.
6.28.2. Threshold methods¶
The final resolution is dependent on the threshold used to assess when the correlation of the image at a given spatial frequency is not significant. Changing the threshold method will change the calculated resolution. The FRC plugin can compute the correlation threshold using the following methods: Fixed; n-Bit information content; or Sigma.
6.28.2.1. Fixed¶
Use the fixed value 1/7 = 0.142857. This is the threshold value preferred by Niewenhuizen, et al (2013) as it provides output that closely matches the apparent resolution of images under manual inspection.
6.28.2.2. n-Bit Information Content (Fourier-Space Signal-to-Noise-Ratio)¶
This method sets the threshold using a level expected for a given information content (Signal-to-Noise Ratio, SNR) in each pixel of the super-resolution image.
The threshold is computed at each frequency (\(T_i\)) for the predefined Fourier-space signal-to-noise ratio (\(\mathit{SNR}_i\)) from the number of data points (\(N_i\)) used to compute the FRC with the following formula:
(see Heel & Schatz, (2005), equation 13). Note that the desired \(\mathit{SNR}_T\) is divided by two since we need half the SNR from each of the half datasets (the two images). For a smoother curve the number of points (\(N_i\)) is computed as \(2\pi r\) and not the actual number of samples computed during the Fourier ring analysis.
The SNR threshold is set using the desired number of bits of information required per pixel using:
Note the use of the binary logarithm. Classically this can be done using n-bits = ½, 1 or 2 bits. For example for a ½ bit curve \(\mathit{SNR}_T=0.4142\) and the formula reduces to:
6.28.2.3. Sigma¶
Compute the threshold at each frequency (\(T_i\)) from the number of data points (\(N_i\)) used to compute the FRC with the following formula:
with \(\sigma\) the sigma-factor (see Heel & Schatz, (2005), equation 2). For example sigma can be 1, 2, 3, etc.
6.28.3. Spurious Correlation (Q) Correction¶
When analysing a single dataset, if the same emitter is localised more than once then this can lead to correlations being observed at all spatial frequencies if localisations from the same emitter are split into each half-dataset (because a non-zero pixel will be present in the same position in both images). These spurious correlations can be corrected by subtracting a term from the numerator of the FRC and adding it to the denominator. The FRC at a given frequency q is given by the sum of the conjugate multiple of the Fourier transform of two sub-images divided by the product of the sums of the squared absolute values of each transformed sub-image:
The sum is computed over all pixels at the specified spatial frequency \(q=|\vec{q}|\) where C denotes the pixels of the perimeter of a circle of constant spatial frequency and q is valued as 0/L, 1/L, 2/L, … with L the pixel size of the input images (1/L is the pixel size in Fourier space). The ring sum can be scaled to a ring mean by dividing by the number of samples in the circle (\(N_C\)):
The correction term is computed as:
where \(Q\) is the average number of activation cycles per emitter (i.e. repeat localisations), \(Q_{\mathit{norm}}\) is a normalisation using the mean pixel value in the input images prior to Fourier transform:
and \(H(q)\) is the factor in the correlation averages related to the localisation uncertainties which is modelled as a Gaussian distribution with mean \(\sigma_m\) and width \(\Delta\sigma\) (in units of super-resolution pixels):
Note that the given equations have been updated from those provided in Niewenhuizen, et al (2013) to those used in the code provided by Bernd Reiger. If Q=0 then no correction is applied. A plugin for estimating Q (the average number of activation cycles per emitter) is provided (see FIRE Q Estimation).
The corrected FRC is thus:
6.28.4. Data Selection¶
The FRC plugin provides the following options to select the localisation data :
Parameters |
Description |
|---|---|
Input |
The results set to analyse. |
Input2 |
The optional second results set to analyse. |
Use ROI / Choose ROI |
If any open images current have an area ROI then the option to choose an ROI is provided. This option is not shown when no ROIs are available. Use ROI is shown when only 1 ROI is available. Choose ROI is shown when multiple ROIs are available. A second dialog will be shown to select the image with the desired ROI. |
If an ROI is selected then the ROI will be scaled from the source image to the bounds of the
input data and only localisations within the bounds selected. An efficient way to produce an appropriate ROI is to construct a super resolution image of the input dataset using the
Results Manager
plugin. An ROI can be drawn on the super resolution image and only that region will be used for the FIRE computation.
6.28.5. Parameters¶
The FRC plugin provides options for each stage of the process:
Image construction
Fourier transform
FIRE analysis
There are also additional options for single dataset processing.
6.28.5.1. Image Construction¶
A super resolution image is required for analysis. If the image is very large then Fourier transform will be slow and may fail due to lack of memory. Options are provided to scale the image automatically to a suitable size for Fourier transform. Localisations are rendered onto the image using bilinear weighting onto the 4 neighbour pixels surrounding the coordinates to reduce pixelation artefacts in the super-resolution image.
Parameters |
Description |
|---|---|
Image scale |
Specify the image enlargement scale to create the super-resolution image from the localisation data. |
Auto image size |
The size for images created with Note that |
Max per bin |
Set above zero to limit the maximum number of localisations that are drawn in each super-resolution pixel. Note: This is set to 5 in Niewenhuizen, et al (2013) to limit the effect of bright spots from anomalous fluorescent molecules. |
6.28.5.2. Fourier Options¶
Parameters |
Description |
|---|---|
Fourier method |
Set the method to compute the Fourier transform. Using the |
Sampling method |
Choose the method to sample pixels on the Fourier ring.
|
Sampling factor |
Affects the number of samples taken using The FRC is calculated by sampling the circle at N points where N is equal to \(\pi r \times \mathit{Sampling\:factor}\). Increasing this value will slow down the algorithm but increase resolution of the FRC curve. Note that samples are taken in the interval \([0, \pi]\) radians since the Fourier image is two-fold radially symmetric. |
6.28.5.3. FIRE Options¶
Parameters |
Description |
|---|---|
Threshold method |
The method for determining the correlation cut-off (see 6.28.2: Threshold methods). |
Show FRC curve |
Display the FRC curve. The curve shows the raw data, the smoothed data and the correlation cut-off. |
6.28.5.4. Single Dataset Processing¶
A single data must be split into two halves to construct the images for analysis. If this split is random then multiple repeats can be performed to provide a mean resolution with a confidence interval. Additionally spurious correlations can be corrected using a Q correction factor (see 6.28.3: Spurious Correlation (Q) Correction).
Parameters |
Description |
|---|---|
Block size |
The number of sequential localisations to assign to a block. Using blocks reduces correlation artefacts from the same molecule occurring in consecutive frames being split into the two images. |
Random Split |
If true then the block data is split randomly into two halves. Otherwise the data is split by alternating blocks. |
Repeats |
If using a Repeats use multi-threaded processing and parallel processing of large images may fail due to available memory. This can be handled by reducing the image size or the number of parallel threads. |
Show FRC curve repeats |
When using repeats only the smoothed curve is added to a combined FRC curve output. Select this option to draw an FRC curve plot with raw and smoothed data for each repeat. |
Show FRC time evolution |
Sort the results by time and compute the FIRE number using 10 step increments up to the max time. This shows how the resolution has changed as the time increases (i.e. more data was collected). This option is computationally intensive and is not currently multi-threaded. |
Spurious correlation correction |
Select this to perform spurious correlation correction. |
Q-value |
The Q correction value. This is the average number of times a molecule is repeat localised. Zero means each molecule is localised only once and no correction is performed. |
Precision mean |
The mean of the Gaussian distribution of the localisation precision. |
Precision sigma |
The standard deviation (width) of the Gaussian distribution of the localisation precision. |
6.28.6. Output¶
The plugin will display progress of the computation on the ImageJ status bar. When the plugin has finished the FIRE number will be reported to the ImageJ log window:
Fit Spot Data : FIRE number = 31.98 nm (Fourier scale = 33.0)
If repeats were performed then the mean resolution is reported with a confidence interval:
Fit Spot Data : FIRE number = 32.95 +/- 0.4573 nm [95% CI, n=10] (Fourier scale = 33.0)
6.28.6.1. FRC Curve¶
The FRC curve data can be very noisy. The data is smoothed using a LOESS smoothing procedure and the crossing points with the correlation cut-off curve are computed. Figure 6.33 shows an example of an FRC curve. The smoothed FRC line crosses the cut-off curve at a frequency of approximately 0.031 nm-1. The resolution is therefore approximately 32nm.
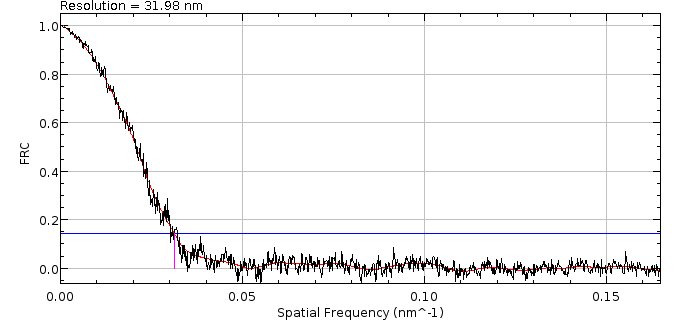
Fig. 6.33 Example FRC curve from the Fourier Image Resolution plugin.¶
The raw FRC data are in black. Smoothed FRC data are in red. The resolution cut-off threshold is in blue at a fixed value of 1/7.
If multiple repeats are performed with randomly split data then a combined curve is produced with all the smoothed curves and the mean resolution (see Figure 6.34).
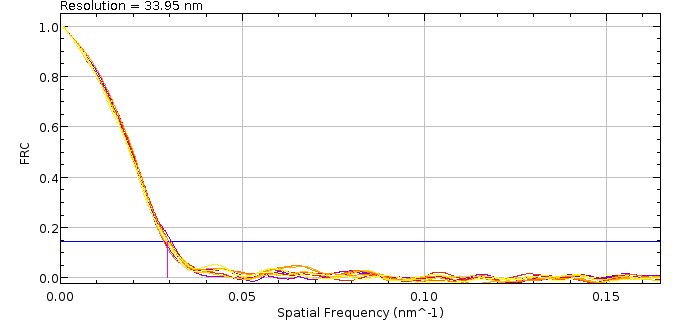
Fig. 6.34 Example combined FRC Curve from 10 repeats of Fourier Image Resolution analysis.¶
6.29. FIRE Q Estimation¶
Estimate the spurious correction factor Q for use in Fourier Image Resolution (FIRE) analysis. Q is the average number of activation cycles per emitter (i.e. repeat localisations).
This plugin is based on the Matlab code kindly provided by Prof. Bernd Reiger (corresponding author of the FIRE paper [Niewenhuizen, et al, 2013]). The method described here is an update to the original method described in the online methods of the FIRE paper.
Fourier Ring Correlation (FRC) computes the correlation between the features of two images at a certain spatial frequency. This correlation is high at low spatial frequencies and progressively reduces. When the correlation falls below a set threshold there is no meaningful similarity information at any further frequency. The spatial frequency at the correlation limit is the Fourier Image Resolution (FIRE).
When analysing a single dataset, if the same emitter is localised more than once then this can lead to correlations being observed at all spatial frequencies if the localisations from the same emitter are split into each half-dataset. These spurious correlations can be corrected by subtracting a term from the numerator of the FRC and adding it to the denominator. The correction term is computed using a factor Q which is the average number of activation cycles per emitter (i.e. repeat localisations), and by assuming the localisations have an uncertainty (precision) that is distributed as a Gaussian with mean \(\sigma_m\) and width \(\Delta\sigma\). This allows the correction to the correlation to be modelled as:
where \(Q_{\mathit{norm}}\) is a normalisation using the mean pixel value in the input images prior to Fourier transform:
and \(H(q)\) is the factor in the correlation averages related to the localisation uncertainties:
and \(\mathbb{sinc}(x) = \sin(x) / x\) (the unnormalised sinc function).
Note that \(H(q)\) is typically computed assuming the theoretical distribution of localisation uncertainties. However it can be constructed using a sample of N points from the actual localisation uncertainties \(\sigma_i\) if they are available:
6.29.1. Estimating Q¶
The true correlation term (due to underlying structure in the data) will decline towards zero at high spatial frequencies. This leaves the spurious correlation term as the main contributor to the FRC numerator at high spatial frequencies. A method for estimating the term involves fitting the model of the correction term to the FRC numerator using a range of spatial frequencies where there is no actual correlation.
There are three terms to estimate: \(Q\), \(\sigma_m\) and \(\Delta\sigma\). If the uncertainty is not available in the dataset then it must be entered as fixed value and only Q will be estimated. If the localisation uncertainty is available for each localisation then it can be estimated using two methods. The first method fits a Gaussian to a histogram of the localisation uncertainty. Alternatively the \(H(q)\) term can be initially constructed using a random sample of the actual localisation uncertainty and the mean estimated from the initial quadratic fit (see below).
The FRC numerator at a given frequency q is given by the sum of the conjugate multiple of the Fourier transform of two sub-images:
The sum is computed over all pixels at the specified spatial frequency \(q=|\vec{q}|\) where C denotes the pixels of the perimeter of a circle of constant spatial frequency and q is valued as 0/L, 1/L, 2/L, … with L the pixel size of the input images (1/L is the pixel size in Fourier space). This term is divided by the number of pixels in the Fourier circle to produce function v(q):
Note that the term \(2\pi q L\) is the circumference of the Fourier circle and is adjusted during computation to be the actual number of samples taken from the Fourier circle.
If the correlation is mainly composed of the spurious correlation then the following relation holds:
Q can thus be estimated using:
This term varies widely in magnitude with q and so the following function is used:
This function is described below equation (7) of the Online Methods of Niewenhuizen, et al (2013). The function f(q) typically is a function that initially decreases, then levels off to a constant plateau value and finally increases again. The function can be well fit using a quadratic (\(f(q)=a+bq^2\)) if the fit is performed over a suitable range of q where the plateau occurs.
To reduce noise the plugin allows smoothing using a median window before application of the absolute and logarithm functions or it can be smoothed afterwards using LOESS smoothing. The Y-intercept is used as an initial estimate of Q:
Note that \(H(q)\) is typically computed assuming the theoretical distribution of localisation uncertainties. However it can be constructed using a random sample of N points from the actual localisation uncertainties. In this case the parameter \(\sigma_m\) can also be estimated from the fit using:
and the other parameter \(\Delta\sigma\) set using the standard deviation of the localisation uncertainty values.
The initial estimate uses a quadratic fit of the function f(q). This estimate is then refined by optimising the parameters so that Corr(q) most closely matches the observed v(q). This is done by optimising the following cost function for all q:
with noise set to a defined level to scale the difference value appropriately. The cost function has a value between 0 and 1 for all observations; a low value is better. Note that Corr(q) is constructed using Q, \(\sigma_m\) and \(\Delta\sigma\) and this second optimisation can be done by fitting Q alone and fixing \(\sigma_m\) and \(\Delta\sigma\), or fitting the 3 parameters together.
6.29.2. Parameters¶
The FRC plugin provides options for each stage of the process:
Data selection
Image construction
Fourier transform
Estimation options
6.29.2.1. Data Selection¶
These are the same as the FIRE plugin (see 6.28: Fourier Image Resolution) without the option for a second dataset. A subset of the data can be selected using an ROI selected from an open image.
6.29.2.2. Image Construction¶
These are the same as the FIRE plugin for single datasets. Note that localisations are drawn using bilinear weighting onto the 4 neighbour pixels surrounding the coordinates to reduce pixelation artefacts in the super-resolution image.
Parameters |
Description |
|---|---|
Image scale |
Specify the image enlargement scale to create the super-resolution image from the localisation data. |
Auto image size |
The size for images created with Note that |
Block size |
The number of sequential localisations to assign to a block. Using blocks reduces correlation artefacts from the same molecule occurring in consecutive frames being split into the two images. |
Random Split |
If true then the block data is split randomly into two halves. Otherwise the data is split by alternating blocks. |
Max per bin |
Set above zero to limit the maximum number of localisations that are drawn in each super-resolution pixel. Note: This is set to 5 in Niewenhuizen, et al (2013) to limit the effect of bright spots from anomalous fluorescent molecules. |
6.29.2.3. Fourier Options¶
These are the same as the FIRE plugin (see 6.28: Fourier Image Resolution).
6.29.2.4. Estimation Options¶
Parameters |
Description |
|---|---|
Threshold method |
The method for determining the correlation cut-off (see 6.28.2: Threshold methods). |
Precision method |
Specify the method to use to determine the parameters for the distribution of the localisation precision (assumed to be Gaussian).
|
Precision Mean |
The mean of the localisation uncertainty (precision) for use in |
Precision Sigma |
The standard deviation of the localisation uncertainty (precision) for use in |
Sample decay |
Set this to true to sample the localisation precision values to generate \(H(q)\) for the initial Q-estimation. \(\sigma_m\) is then also estimated from the initial fit. The default generates \(H(q)\) using \(\sigma_m\) and \(\Delta\sigma\) from the |
LOESS smoothing |
Smooth the curve f(q) using LOESS smoothing. The default smooths the data using a median window before applying the absolute and logarithm functions. |
Fit precision |
Set to true to optimise \(\sigma_m\) and \(\Delta\sigma\) when fitting v(q) to Corr(q). The default only optimises the Q-value. |
MinQ |
The minimum spatial frequency q value to use for fitting. |
MaxQ |
The maximum spatial frequency q value to use for fitting. |
Note: q is specified in terms of the Fourier image width so has a range from 0 to 0.5. Choose a range for q where the correlation has fallen off from the initial high value to approach 0, i.e. the range where the correlation is mainly due to spurious correlations between repeats of the same molecule.
6.29.3. Output¶
The plugin will display progress of the computation on the ImageJ status bar. When the plugin has finished the results are presented graphically. A non-blocking dialog is used to allow the user to adjust the estimated values and the displayed results are dynamically updated.
6.29.3.1. Precision Histogram¶
The histogram of the localisation uncertainty (precision) is displayed with an overlay of the current mean and standard deviation (Figure 6.35) . If no precision is available then only the overlay is shown.
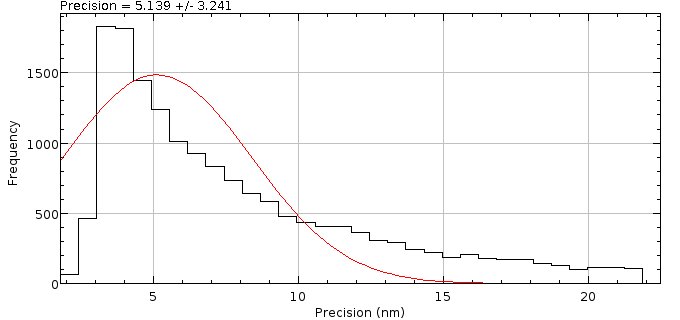
Fig. 6.35 FIRE Q estimation precision histogram plot¶
6.29.3.2. FRC Numerator Curve¶
The FRC numerator function, v(q), is plotted against the correction, Corr(q) (see Figure 6.36). The corrected numerator is also plotted to show the effect of correction.
Note that the purpose of the plugin is to maximise the fit between the numerator and the correction within the selected fitting range of q. The range is shown using magenta vertical lines. Ideally the range should exclude the low frequencies where the numerator is significantly different from the correction due to actual correlation within the dataset.
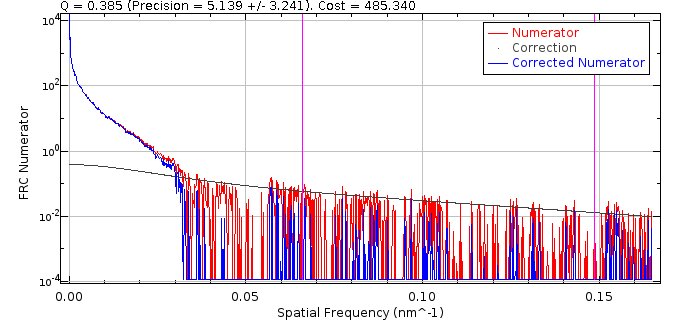
Fig. 6.36 FIRE Q estimation FRC numerator plot¶
6.29.3.3. FRC Numerator/Correction Ratio¶
The cost function aims to minimise:
over a selected range of q, where g(x) is a mapping function with value 0 when x is zero and a maximum value of 1. Thus the ideal ratio \(v(q) / \mathit{Corr}(q)\) is 1. The Numerator/Correction Ratio plot (see Figure 6.37) shows \(v(q) / \mathit{Corr}(q)\). The range is set to 0-2 and a line drawn at 1 for the ideal value. The fit range for q is shown using magenta vertical lines. This plot is often very noisy indicating that optimising the fit is non-trivial and sub-optimal results may occur (i.e. estimation has failed).
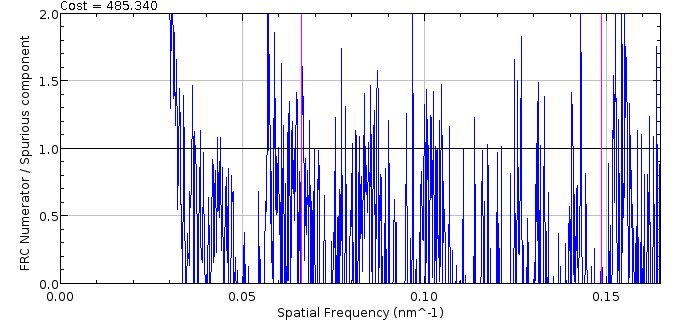
Fig. 6.37 FIRE Q estimation FRC numerator/correction ratio plot¶
6.29.3.4. FRC Curve¶
The FRC curve (Figure 6.38) is similar to that shown by the FIRE plugin (see section 6.28). The raw data of the correlation is shown in black and the smoothed line in red. The resolution is computed using the crossing point with the threshold curve (blue). If the Q-value is above zero then the original data is shown with 50% opacity. The resolution before and after Q correction are shown in the label.
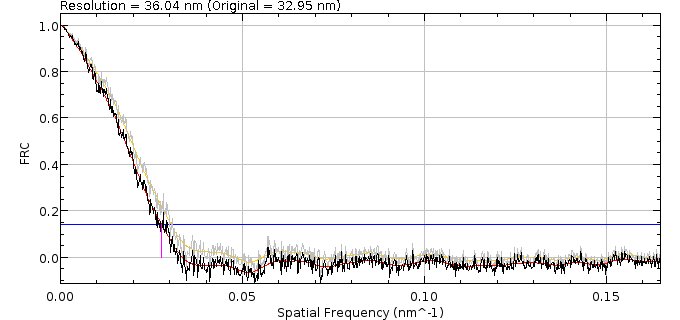
Fig. 6.38 FIRE Q estimation FRC curve plot¶
6.29.3.5. Interactive Q-Estimation¶
Once the plots have been displayed the plugin shows a dialog (Figure 6.39) containing the initial estimates for Q, \(\sigma_m\) and \(\Delta\sigma\) and the value of the cost function. This is a non-blocking dialog and so allows the user to move other ImageJ windows to optimise the layout.
Fig. 6.39 FIRE Q estimation interactive dialog¶
The user can adjust any of the current parameter values and see the effects on the plots dynamically. The cost function value is updated and shown so that the effects of manual estimation can be compared to the initial auto-estimation. Adjustments can be made to the slider or by editing the text field value. Note that the estimate values are magnified 10-fold to allow finer adjustment of the estimates. This is due to the limited functionality of sliders within ImageJ dialogs.
The Reset all button can be used to set the values back to the initial estimates, for example if adjustments have significantly changed the cost function. Alternatively a double-click on a single slider will reset only that slider.
Clicking the OK button will close the dialog and the current estimates are saved to memory. These values will be used in the FIRE plugin for the fields for spurious correlation correction.
Clicking the Cancel button will close the dialog without saving the current estimates.